 Sanjeeva Srivastava, Ph.D.
Sanjeeva Srivastava, Ph.D.
Assistant Professor, Proteomics Lab, IIT-Bombay, India
Identification of Potential Early Diagnostic Biomarkers for Gliomas and Various Infectious Diseases using Proteomic Technologies
The spectacular advancements achieved in the field of proteomics research during the last decade have propelled the growth of proteomics for clinical research. Recently, comprehensive proteomic analyses of different biological samples such as serum or plasma, tissue, CSF, urine, saliva etc. have attracted considerable attention for the identification of protein biomarkers as early detection surrogates for diseases (Ray et al., 2011). Biomarkers are biomolecules that can be used for early disease detection, differentiation between closely related diseases with similar clinical manifestations as well as aid in scrutinizing disease progression. Our research group is performing in-depth analysis of alteration in human proteome in different types of brain tumors and various pathogenic infections to obtain mechanistic insight about the disease pathogenesis and host immune responses, and identification of surrogate protein markers for these fatal human diseases.
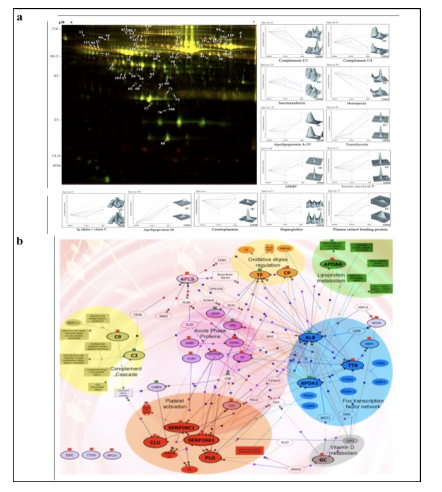
Applying 2D-DIGE in combination with MALDI-TOF/TOF MS we have analyzed the serum and tissue proteome profiles of glioblastoma multiforme; the most common and lethal adult malignant brain tumor (Gollapalli et al., 2012) (Figure 1). Results obtained were validated by employing different immunoassay-based approaches. In serum proteomic analysis we have identified some interesting proteins like haptoglobin, ceruloplasmin, vitamin-D binding protein etc. Moreover, proteomic analysis of different grades (grade-I to IV) of gliomas and normal brain tissue was performed and differential expressions of quite a few proteins such as SIRT2, GFAP, SOD, CDC42 have been identified, which have significant correlation with the tumor growth. While proteomic analysis of cerebrospinal fluid from low grade (grade I & II) vs. high grade (grade III & IV) gliomas revealed modulation of CSF levels of apolipoprotein E, dickkopf related protein 3, vitamin D binding protein and albumin in high grade gliomas. The prospective candidates identified in our studies provide a mechanistic insight of glioma pathogenesis and identification of potential biomarkers. We are also studying the role of JAK/STAT interactome and therapeutic potential of STAT3 inhibitors in gliomas using proteomics approach. Several candidates of the JAK/STAT interactome were identified with altered expression and a significant correlation was observed between STAT3 and PDK1 transcript expression level.
We have also investigated the changes in human serum proteome in different infectious diseases including falciparum and vivax malaria (Ray et al., 2012a; Ray et al., 2012b), dengue (Ray et al., 2012c) and leptospirosis (Srivastava et al., 2012). Although, quite a few serum proteins were found to be commonly altered in different infectious diseases and might be a consequence of inflammation mediated acute phase response signaling, uniquely modulated candidates were identified in each pathogenic infection indicating the some inimitable responses. Further, a panel of identified proteins consists of six candidates; serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I was used to build statistical sample class prediction models employing PLSDA and other classification methods to predict the clinical phenotypic classes and 91.37% overall prediction accuracy was achieved (Figure 2). ROC curve analysis was carried out to evaluate the individual performance of classifier proteins. The excellent discrimination among the different disease groups on the basis of differentially expressed proteins demonstrates the potential diagnostic implications of this analytical approach.
Keywords: Diagnostic biomarkers, Gliomas, Infectious Diseases, Proteomics, Serum proteome
Acknowledgments: This disease biomarker discovery research was supported by Department of Biotechnology, India grant (No. BT/PR14359/MED/30/916/2010), Board of Research in Nuclear Sciences (BRNS) DAE young scientist award (2009/20/37/4/BRNS) and a startup grant 09IRCC007 from the IIT Bombay. The active support from Advanced Center for Treatment Research and Education in Cancer (ACTREC), Tata Memorial Hospital (TMH), and Seth GS Medical College and KEM Hospital Mumbai, India in clinical sample collection process is gratefully acknowledged.
References :
- Ray S, Reddy PJ, Jain R, Gollapalli K. Moiyadi A, Srivastava S. Proteomic technologies for the identification of disease biomarkers in serum: advances and challenges ahead. Proteomics 11: 2139-61, 2011.
- Gollapalli K, Ray S, Srivastava R, Renu D, Singh P, Dhali S, Dikshit JB, Srikanth R, Moiyadi A, Srivastava S. Investigation of serum proteome alterations in human glioblastoma multiforme. Proteomics 12(14): 2378-90, 2012.
- Ray S, Renu D, Srivastava R, Gollapalli K, Taur S, Jhaveri T, Dhali S, Chennareddy S, Potla A, Dikshit JB, Srikanth R, Gogtay N, Thatte U, Patankar S, Srivastava S. Proteomic investigation of falciparum and vivax malaria for identification of surrogate protein markers. PLoS One 7(8): e41751, 2012a.
- Ray S, Kamath KS, Srivastava R, Raghu D, Gollapalli K, Jain R, Gupta SV, Ray S, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Patankar S, Srivastava S. Serum proteome analysis of vivax malaria: An insight into the disease pathogenesis and host immune response. J Proteomics 75(10): 3063-80, 2012b.
- Srivastava R, Ray S, Vaibhav V, Gollapalli K, Jhaveri T, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Srivastava S. Serum profiling of leptospirosis patients to investigate proteomic alterations. J Proteomics 76: 56-68, 2012.
- Ray S, Srivastava R, Tripathi K, Vaibhav V, Srivastava S. Serum proteome changes in dengue virus-infected patients from a dengue-endemic area of India: towards new molecular targets? OMICS 16(10): 527-36, 2012c.
* Correspondence: Dr. Sanjeeva Srivastava, Department of Biosciences and Bioengineering, IIT Bombay, Mumbai 400 076, India: E-mail: sanjeeva@iitb.ac.in; Phone: +91-22-2576-7779, Fax: +91-22-2572-3480
![Figure 2 (a) Western blot analysis of haptoglobin (HP), serum amyloid A (SAA), and clusterin (CLU) from serum samples of healthy control (HC) [n = 12], falciparum malaria (FM) [n = 12], vivax malaria (VM) [n = 12], Leptospirosis (Lep) [n = 6], dengue fever [DF] [n = 6] and non infectious disease control (NIDC:GBM) [n = 12]. Representative blots of the target proteins are depicted along with their respective relative abundance volumes (volume X 104). All the data are represented as mean ± SE. (b) Discrimination of malaria from dengue, leptospirosis and GBM using PLS-DA analysis. PLS-DA scores Plot for FM (blue spheres, n = 8), VM (green spheres, n = 8), DF (red spheres, n = 6), Lep (grey spheres, n = 6) and GBM (brown spheres, n = 8) samples based on 6 differentially expressed proteins (serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I) identified using DIGE. The axes of the plot indicate PLSDA latent variables t0-t2.](http://www.amritabioquest.org/conference/2013/wp-content/uploads/sites/2/2015/02/sanjeeva-2.jpg)


 Rajgopal Srinivasan, Ph.D.
Rajgopal Srinivasan, Ph.D.
Principal Scientist & Head Bio IT R&D, TCS Innovation Labs, India
Interpretation of Genomic Variation – Identifying Rare Variations Leading to Disease
Genome sequencing technologies are generating an abundance of data on human genetic variations. A big challenge lies in interpreting the functional relevance of such variations, especially in clinical settings. A first step in understanding the clinical relevance of genetic variations is to annotate the variants for region of occurrence, degree of conservation both within and across species, pattern of variation across related individuals, novelty of the variation and know effects of related variations. Several tools already exist for this purpose. However, these tools have their strengths and weaknesses. A second issue is the development of algorithms, which, given a rich annotation of variants are able to prioritize the variants as being relevant to the phenotype under investigation.
In my talk I will detail work that has been done in our labs to address both of the above problems. I will also illustrate the application of these tools that helped identify a rare mutation in the ATM gene leading to a diagnosis of AT in two infants.
 Kal Ramnarayan, Ph.D.
Kal Ramnarayan, Ph.D.
Co-founder President & Chief Scientific Officer, Sapient Discovery, San Diego, CA, USA
A cost-effective approach to Protein Structure-guided Drug Discovery: Aided by Bioinformatics, Chemoinformatics and computational chemistry
With the mapping of the human genome completed almost a decade ago, efforts are still underway to understand the gene products (i.e., proteins) in the human biological and disease pathways. Deciphering such information is very important for the discovery and development of small molecule drugs as well as protein therapeutics for various human diseases for which no cure exists. As an example, with more than 500 members, the kinase family of protein targets continues to be an important and attractive class for drug discovery. While how many of the members in this family are actually druggable is still to be established, there are several ongoing efforts on this class of proteins across a broad spectrum of disease categories. Even though in general the protein structural topology might looks similar, there are issues with respect selectivity of identified small molecule inhibitors when, the lead molecule discovery is carried out at the ATP binding site. As an added complexity, allosteric modulators are needed for some of the members, but the actual site for such modulation on the protein target can not resolved with uncertainty. In this presentation we will describe a bioinformatics and computational based platform for small molecule discovery for protein targets that are involved in protein-protein interactions as well as targets like kinases and phosphatases. We will describe a computational approach in which we have used an informatics based platform with several hundred kinases to sort through in silico and identify inhibitors that are likely to be highly selective in the lead generation phase. We will discuss the implication of this approach on the drug discovery of the kinase and phosphatase classes in general and independent of the disease category.
 Lalitha Subramanian, Ph.D.
Lalitha Subramanian, Ph.D.
Chief Scientific Officer & VP, Services at Scienomics, USA
Nanoscale Simulations – Tackling Form and Formulation Challenges in Drug Development and Drug Delivery
Lalitha Subramanian, Dora Spyriouni, Andreas Bick, Sabine Schweizer, and Xenophon Krokidis Scienomics
The discovery of a compound which is potent in activity against a target is a major milestone in Pharmaceutical and Biotech industry. However, a potent compound is only effective as a therapeutic agent when it can be administered such that the optimal quantity is transported to the site of action at an optimal rate. The active pharmaceutical ingredient (API) has to be tested for its physicochemical properties before the appropriate dosage form and formulation can be designed. Some of the commonly evaluated parameters are crystal forms and polymorphs, solubility, dissolution behavior, stability, partition coefficient, water sorption behavior, surface properties, particle size and shape, etc. Pharmaceutical development teams face the challenge of quickly and efficiently determining a number of properties with small quantities of the expensive candidate compounds. Recently the trend has been to screen these properties as early as possible and often the candidate compounds are not available in sufficient quantities. Increasingly, these teams are leveraging nanoscale simulations similar to those employed by drug discovery teams for several decades. Nanoscale simulations are used to predict the behavior using very little experimental data and only if this is promising further experiments are done. Another aspect where nanoscale simulations are being used in drug development and drug delivery is to get insights into the behavior of the system so that process failures can be remediated and formulation performance can be improved. Thus, the predictive screening and the in-depth understanding leads to experimental efficiency resulting in far-reaching business impacts.
With specific examples, this talk will focus on the different types of nanoscale simulations used to predict properties of the API in excipients and also provide insight into system behavior as a function of shelf life, temperature, mechanical stress, etc.

Aswath Balakrishnan, Kapaettu Satyamoorthy and Manjunath B Joshi
Introduction
Insulin resistance is a hall mark of metabolic disorders such as diabetes. Reduced insulin response in vasculature leads to disruption of IR/Akt/eNOS signaling pathway resulting in vasoconstriction and subsequently to cardiovascular diseases. Recent studies have demonstrated that inflammatory regulator interleukin-6 (IL-6), as one of the potential mediators that can link chronic inflammation with insulin resistance. Accumulating evidences suggest a significant role of epigenetic mechanisms such as DNA methylation in progression of metabolic disorders. Hence the present study aimed to understand the role of epigenetic mechanisms involved during IL-6 induced vascular insulin resistance and its consequences in cardiovascular diseases.
Materials and Methods
Human umbilical vein endothelial cells (HUVEC) and Human dermal microvascular endothelial cells (HDMEC) were used for this study. Endothelial cells were treated in presence or absence of IL-6 (20ng/ml) for 36 hours and followed by insulin (100nM) stimulation for 15 minutes. Using immunoblotting, cell lysates were stained for phosphor- and total Akt levels to measure insulin resistance. To investigate changes in DNA methylation, cells were treated with or without neutrophil conditioned medium (NCM) as a physiological source of inflammation or IL-6 (at various concentrations) for 36 hours. Genomic DNA was processed for HPLC analysis for methyl cytosine content and cell lysates were analyzed for DNMT1 (DNA (cytosine-5)-methyltransferase 1) and DNMT3A (DNA (cytosine-5)-methyltransferase 3A) levels using immunoblotting.
Results
Endothelial cells stimulated with insulin exhibited an increase in phosphorylation of Aktser 473 in serum free conditions but such insulin response was not observed in cells treated with IL-6, suggesting chronic exposure of endothelial cells to IL-6 leads to insulin resistance. HPLC analysis for global DNA methylation resulted in decreased levels of 5-methyl cytosine in cells treated with pro-inflammatory molecules (both by NCM and IL-6) as compared to untreated controls. Subsequently, analysis in cells treated with IL-6 showed a significant decrease in DNMT1 levels but not in DNMT3A. Other pro-inflammatory marker such as TNF-α did not exhibit such changes.
Conclusion
Our study suggests: a) Chronic treatment of endothelial cells with IL-6 results in insulin resistance b) Neutrophil conditioned medium and IL-6 decreases methyl cytosine levels c) DNMT1 but not DNMT3a levels are reduced in cells treated with IL-6.
 Sudarslal S, Ph.D.
Sudarslal S, Ph.D.
Associate Professor, School of Biotechnology, Amrita University
Electrospray ionization ion trap mass spectrometry for cyclic peptide characterization
There has been considerable interest in the isolation and structural characterization of bioactive peptides produced by bacteria and fungi. Most of the peptides are cyclic depsipeptides characterized by the presence of lactone linkages and β-hydroxy fatty acids. Occurrence of microheterogeneity is another remarkable property of these peptides. Even if tandem mass spectrometers are good analytical tools to structurally characterize peptides and proteins, sequence analysis of cyclic peptides is often ambiguous due to the random ring opening of the peptides and subsequent generation of a set of linear precursor ions with the same m/z. Here we report combined use of chemical derivatization and multistage fragmentation capability of ion trap mass spectrometers to determine primary sequences of a series of closely related cyclic peptides.



Ravindra Gudihal, Suresh Babu C V
Bioanalytical Characterization of Therapeutic Proteins
The characterization of therapeutic proteins such as monoclonal antibody (mAb) during different stages of manufacturing is crucial for timely and successful product release. Regulatory agencies require a variety of analytical technologies for comprehensive and efficient protein analysis. Electrophoresis-based techniques and liquid chromatography (LC) either standalone or coupled to mass spectrometry (MS) are at the forefront for the in-depth analysis of protein purity, isoforms, stability, aggregation, posttranslational modifications, PEGylation, etc. In this presentation, a combination of various chromatographic and electrophoretic techniques such as liquid-phase isoelectric focusing, microfluidic and capillary-based electrophoresis (CE), liquid chromatography (LC) and combinations of those with mass spectrometry techniques will be discussed. We present a workflow based approach to the analysis of therapeutic proteins. In successive steps critical parameters like purity, accurate mass, aggregation, peptide sequence, glycopeptide and glycan analysis are analyzed. In brief, the workflow involved proteolytic digestion of therapeutic protein for peptide mapping, N-Glycanase and chemical labeling reaction for glycan analysis, liquid-phase isoelectric focusing for enrichment of charge variants followed by a very detailed analysis using state of the art methods such as CE-MS and LC-MS. For the analysis of glycans, we use combinations of CE-MS and LC-MS to highlight the sweet spots of these techniques. CE-MS is found to be more useful in analysis of highly sialylated glycans (charged glycans) while nano LC-MS seems to be better adapted for analysis of neutral glycans. These two techniques can be used to get complementary data to profile all the glycans present in a given protein. In addition, microfluidic electrophoresis was used as a QC tool in initial screening for product purity, analysis of papain digestion fragments of mAb, protein PEGylation products, etc. The described workflow involves multiple platforms, provides an end to end solution for comprehensive protein characterization and aims at reducing the total product development time.