 Upinder S. Bhalla, Ph.D.
Upinder S. Bhalla, Ph.D.
Professor & Dean, NCBS, Bengaluru, India
Watching the network change during the formation of associative memory
The process of learning is measured through behavioural changes, but it is of enormous interest to understand its cellular and network basis. We used 2-photon imaging of hippocampal CA1 pyramidal neuron activity in mice to monitor such changes during the acquisition of a trace conditioning task. One of the questions in such learning is how the network retains a trace of a brief conditioned stimulus (a sound), until the arrival of a delayed unconditioned stimulus (a puff of air to the eye). During learning, the mice learn to blink when the tone is presented, well before the arrival of the air puff.
The mice learnt this task in 20-50 trials. We observed that in this time-frame the cells in the network changed the time of their peak activity, such that their firing times tiled the interval between sound and air puff. Thus the cells seem to form a relay of activity. We also observed an evolution in functional connectivity in the network, as measured by groupings of correlated cells. These groupings were stable till the learning protocol commenced, and then changed. Thus we have been able to observe two aspects of network learning: changes in activity (relay firing), and changes in connectivity (correlation groups).


 Sanjeeva Srivastava, Ph.D.
Sanjeeva Srivastava, Ph.D.
Assistant Professor, Proteomics Lab, IIT-Bombay, India
Identification of Potential Early Diagnostic Biomarkers for Gliomas and Various Infectious Diseases using Proteomic Technologies
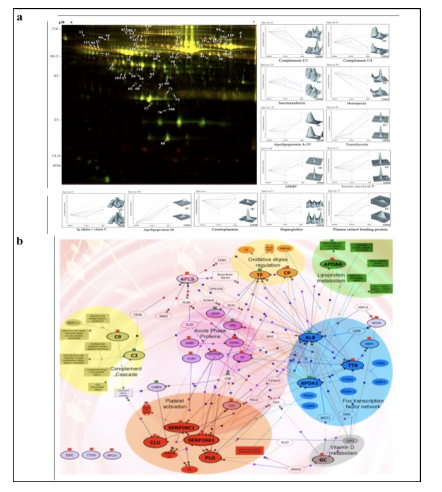
The spectacular advancements achieved in the field of proteomics research during the last decade have propelled the growth of proteomics for clinical research. Recently, comprehensive proteomic analyses of different biological samples such as serum or plasma, tissue, CSF, urine, saliva etc. have attracted considerable attention for the identification of protein biomarkers as early detection surrogates for diseases (Ray et al., 2011). Biomarkers are biomolecules that can be used for early disease detection, differentiation between closely related diseases with similar clinical manifestations as well as aid in scrutinizing disease progression. Our research group is performing in-depth analysis of alteration in human proteome in different types of brain tumors and various pathogenic infections to obtain mechanistic insight about the disease pathogenesis and host immune responses, and identification of surrogate protein markers for these fatal human diseases.
Applying 2D-DIGE in combination with MALDI-TOF/TOF MS we have analyzed the serum and tissue proteome profiles of glioblastoma multiforme; the most common and lethal adult malignant brain tumor (Gollapalli et al., 2012) (Figure 1). Results obtained were validated by employing different immunoassay-based approaches. In serum proteomic analysis we have identified some interesting proteins like haptoglobin, ceruloplasmin, vitamin-D binding protein etc. Moreover, proteomic analysis of different grades (grade-I to IV) of gliomas and normal brain tissue was performed and differential expressions of quite a few proteins such as SIRT2, GFAP, SOD, CDC42 have been identified, which have significant correlation with the tumor growth. While proteomic analysis of cerebrospinal fluid from low grade (grade I & II) vs. high grade (grade III & IV) gliomas revealed modulation of CSF levels of apolipoprotein E, dickkopf related protein 3, vitamin D binding protein and albumin in high grade gliomas. The prospective candidates identified in our studies provide a mechanistic insight of glioma pathogenesis and identification of potential biomarkers. We are also studying the role of JAK/STAT interactome and therapeutic potential of STAT3 inhibitors in gliomas using proteomics approach. Several candidates of the JAK/STAT interactome were identified with altered expression and a significant correlation was observed between STAT3 and PDK1 transcript expression level.
We have also investigated the changes in human serum proteome in different infectious diseases including falciparum and vivax malaria (Ray et al., 2012a; Ray et al., 2012b), dengue (Ray et al., 2012c) and leptospirosis (Srivastava et al., 2012). Although, quite a few serum proteins were found to be commonly altered in different infectious diseases and might be a consequence of inflammation mediated acute phase response signaling, uniquely modulated candidates were identified in each pathogenic infection indicating the some inimitable responses. Further, a panel of identified proteins consists of six candidates; serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I was used to build statistical sample class prediction models employing PLSDA and other classification methods to predict the clinical phenotypic classes and 91.37% overall prediction accuracy was achieved (Figure 2). ROC curve analysis was carried out to evaluate the individual performance of classifier proteins. The excellent discrimination among the different disease groups on the basis of differentially expressed proteins demonstrates the potential diagnostic implications of this analytical approach.
Keywords: Diagnostic biomarkers, Gliomas, Infectious Diseases, Proteomics, Serum proteome
Acknowledgments: This disease biomarker discovery research was supported by Department of Biotechnology, India grant (No. BT/PR14359/MED/30/916/2010), Board of Research in Nuclear Sciences (BRNS) DAE young scientist award (2009/20/37/4/BRNS) and a startup grant 09IRCC007 from the IIT Bombay. The active support from Advanced Center for Treatment Research and Education in Cancer (ACTREC), Tata Memorial Hospital (TMH), and Seth GS Medical College and KEM Hospital Mumbai, India in clinical sample collection process is gratefully acknowledged.
References :
- Ray S, Reddy PJ, Jain R, Gollapalli K. Moiyadi A, Srivastava S. Proteomic technologies for the identification of disease biomarkers in serum: advances and challenges ahead. Proteomics 11: 2139-61, 2011.
- Gollapalli K, Ray S, Srivastava R, Renu D, Singh P, Dhali S, Dikshit JB, Srikanth R, Moiyadi A, Srivastava S. Investigation of serum proteome alterations in human glioblastoma multiforme. Proteomics 12(14): 2378-90, 2012.
- Ray S, Renu D, Srivastava R, Gollapalli K, Taur S, Jhaveri T, Dhali S, Chennareddy S, Potla A, Dikshit JB, Srikanth R, Gogtay N, Thatte U, Patankar S, Srivastava S. Proteomic investigation of falciparum and vivax malaria for identification of surrogate protein markers. PLoS One 7(8): e41751, 2012a.
- Ray S, Kamath KS, Srivastava R, Raghu D, Gollapalli K, Jain R, Gupta SV, Ray S, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Patankar S, Srivastava S. Serum proteome analysis of vivax malaria: An insight into the disease pathogenesis and host immune response. J Proteomics 75(10): 3063-80, 2012b.
- Srivastava R, Ray S, Vaibhav V, Gollapalli K, Jhaveri T, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Srivastava S. Serum profiling of leptospirosis patients to investigate proteomic alterations. J Proteomics 76: 56-68, 2012.
- Ray S, Srivastava R, Tripathi K, Vaibhav V, Srivastava S. Serum proteome changes in dengue virus-infected patients from a dengue-endemic area of India: towards new molecular targets? OMICS 16(10): 527-36, 2012c.
* Correspondence: Dr. Sanjeeva Srivastava, Department of Biosciences and Bioengineering, IIT Bombay, Mumbai 400 076, India: E-mail: sanjeeva@iitb.ac.in; Phone: +91-22-2576-7779, Fax: +91-22-2572-3480
![Figure 2 (a) Western blot analysis of haptoglobin (HP), serum amyloid A (SAA), and clusterin (CLU) from serum samples of healthy control (HC) [n = 12], falciparum malaria (FM) [n = 12], vivax malaria (VM) [n = 12], Leptospirosis (Lep) [n = 6], dengue fever [DF] [n = 6] and non infectious disease control (NIDC:GBM) [n = 12]. Representative blots of the target proteins are depicted along with their respective relative abundance volumes (volume X 104). All the data are represented as mean ± SE. (b) Discrimination of malaria from dengue, leptospirosis and GBM using PLS-DA analysis. PLS-DA scores Plot for FM (blue spheres, n = 8), VM (green spheres, n = 8), DF (red spheres, n = 6), Lep (grey spheres, n = 6) and GBM (brown spheres, n = 8) samples based on 6 differentially expressed proteins (serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I) identified using DIGE. The axes of the plot indicate PLSDA latent variables t0-t2.](http://www.amritabioquest.org/conference/2013/wp-content/uploads/sites/2/2015/02/sanjeeva-2.jpg)


 Leland H. Hartwell Ph.D.
Leland H. Hartwell Ph.D.
2001 Nobel Laureate, Physiology & Medicine
Dr. Lee Hartwell received the 2001 Nobel Prize in Physiology / Medicine for his discovery of protein molecules that control the division of cells. He was the President and Director of the Fred Hutchinson Cancer Research Center in Seattle, Washington before moving to Arizona State University’s Center for Sustainable Health.
Dr. Hartwell is also adjunct faculty at Amrita University. He spoke to the delegates at Bioquest from his office in the US, over Amrita’s e-learning platform A-View. Given below are excerpts from his address.
I would like to address the young people in the audience. I know that many of you may have come to this meeting wondering, “How can I become a successful scientist? How can I prepare myself to make a contribution in this world?”
These questions are interesting to me also.
Believe it or not, I am still trying to be a successful scientist. That may surprise you since you probably think that a Nobel laureate must have found the answers. But the problem is that the answers to these questions change with time and the answers are different today than what they were when I began my career fifty years ago. The strategy of the 1960’s doesn’t work so well anymore. What is different now?
First, what we know now is much more. For example, by 1970, no genes from any organisms were sequenced. In 2013, we have the complete sequence of the human genome. Second, not only do we know much more today, accessing that knowledge is easy. Third, obtaining new information is much faster today.
Our rich understanding of science and technology is now needed to solve many serious problems. The human population has reached the size where we are utilizing all available resource of the planet. We are utilizing all of the agricultural land, all of the water, all of the forest and fishing resources. We are also polluting the planet that we live on.
We are polluting the land with fertilizers and pesticides; the oceans with acids and the atmosphere with carbon dioxide. We are using up top soil and ground water, thereby reducing our capacity to feed ourselves. We are using up petroleum, the energy source that our entire economy is dependent on. These are problems we were largely unaware of, fifty years ago. But these are problems that must be solved in your life times.
The big question facing your generation is, how can human beings live sustainably on planet earth. Your two broad goals on sustainability are 1) leave the planet as you first found it for your future generations; don’t use up the resources and don’t pollute the planet 2) everyone deserves to have an equal share of the earth’s resources.
Income strongly determines one’s opportunities in life. Many poor people succumb to chronic diseases and unhealthy environments. This inequality undermines our ability to live sustainably. We can’t ask the poor to leave the planet as they found it if they can’t support their families. Education, healthcare, employment are essential to having a sustainable society.
How can we be a successful scientist in 2013?
1. First choose a problem to solve
2. Ask questions to understand why it is not solved
3. Collaborate with those who can help
4. Develop a solution that works in the real worldChronic diseases are our major burden and this burden will get worse. Heart disease, diabetes, cancer, dementia and other diseases. The good news is that the chronic diseases are largely preventable and more easily curable if detected early. One question that attracts me is how can we detect disease earlier when it can be more easily cured?
Can we use our increasing knowledge in molecular biology to identify biomarkers for early disease detection?
We need to collaborate very closely with clinicians who care for patients to find out exactly where they need help.
I think if we apply our technology to important clinical questions we will actually save medical expenditure and be well on our way to making a great contribution to society.



 D. Narasimha Rao, Ph.D.
D. Narasimha Rao, Ph.D.
Professor, Dept of Biochemistry, Indian Institute of Science, Bangalore, India
Genomics of Restriction-Modification Systems
Restriction endonucleases occur ubiquitously among procaryotic organisms. Up to 1% of the genome of procaryotic organisms is taken up by the genes for these enzymes. Their principal biological function is the protection of the host genome against foreign DNA, in particular bacteriophage DNA. Restriction-modification (R-M) systems are composed of pairs of opposing enzyme activities: an endonuclease and a DNA methyltransferase (MTase). The endonucleases recognise specific sequences and catalyse cleavage of double-stranded DNA. The modification MTases catalyse the addition of a methyl group to one nucleotide in each strand of the recognition sequence using S-adenosyl-L-methionine (AdoMet) as the methyl group donor. Based on their molecular structure, sequence recognition, cleavage position and cofactor requirements, R-M systems are generally classified into three groups. In general R-M systems restrict unmodified DNA, but there are other systems that specifically recognise and cut modified DNA. More than 3500 restriction enzymes have been discovered so far. With the identification and sequencing of a number of R-M systems from bacterial genomes, an increasing number of these have been found that do not seem to fit into the conventional classification.
It is well documented that restriction enzyme genes always lie close to their cognate methyltransferase genes. Analysis of the bacterial and archaeal genome sequences shows that MTase genes are more common than one would have expected on the basis of previous biochemical screening. Frequently, they clearly form part of a R-M system, because the adjacent open reading frames (ORFs) show similarity to known restriction enzyme genes. Very often, though, the adjacent ORFs have no homologs in the GenBank and become candidates either for restriction enzymes with novel specificities or for new examples of previously uncloned specificities. Sequence-dependent modification and restriction forms the foundation of defense against foreign DNAs and thus RM systems may serve as a tool of defense for bacterial cells. RM systems however, sometimes behave as discrete units of life, and any threat to their maintenance, such as a challenge by a competing genetic element can lead to cell death through restriction breakage in the genome, thus providing these systems with a competitive advantage. The RM systems can behave as mobile-genetic elements and have undergone extensive horizontal transfer between genomes causing genome rearrangements. The capacity of RM systems to act as selfish, mobile genetic elements may underlie the structure and function of RM enzymes.
The similarities and differences in the different mechanisms used by restriction enzymes will be discussed. Although it is not clear whether the majority of R-M systems are required for the maintenance of the integrity of the genome or whether they are spreading as selfish genetic elements, they are key players in the “genomic metabolism” of procaryotic organisms. As such they deserve the attention of biologists in general. Finally, restriction enzymes are the work horses of molecular biology. Understanding their enzymology will be advantageous to those who use these enzymes, and essential for those who are devoted to the ambitious goal of changing the properties of these enzymes, and thereby make them even more useful.

 Kal Ramnarayan, Ph.D.
Kal Ramnarayan, Ph.D.
Co-founder President & Chief Scientific Officer, Sapient Discovery, San Diego, CA, USA
A cost-effective approach to Protein Structure-guided Drug Discovery: Aided by Bioinformatics, Chemoinformatics and computational chemistry
With the mapping of the human genome completed almost a decade ago, efforts are still underway to understand the gene products (i.e., proteins) in the human biological and disease pathways. Deciphering such information is very important for the discovery and development of small molecule drugs as well as protein therapeutics for various human diseases for which no cure exists. As an example, with more than 500 members, the kinase family of protein targets continues to be an important and attractive class for drug discovery. While how many of the members in this family are actually druggable is still to be established, there are several ongoing efforts on this class of proteins across a broad spectrum of disease categories. Even though in general the protein structural topology might looks similar, there are issues with respect selectivity of identified small molecule inhibitors when, the lead molecule discovery is carried out at the ATP binding site. As an added complexity, allosteric modulators are needed for some of the members, but the actual site for such modulation on the protein target can not resolved with uncertainty. In this presentation we will describe a bioinformatics and computational based platform for small molecule discovery for protein targets that are involved in protein-protein interactions as well as targets like kinases and phosphatases. We will describe a computational approach in which we have used an informatics based platform with several hundred kinases to sort through in silico and identify inhibitors that are likely to be highly selective in the lead generation phase. We will discuss the implication of this approach on the drug discovery of the kinase and phosphatase classes in general and independent of the disease category.
 V. Nagaraja Ph.D.
V. Nagaraja Ph.D.
Professor, Indian Institute of Science, Bengaluru, India
Perturbation of DNA topology in mycobacteria
To maintain the topological homeostasis of the genome in the cell, DNA topoisomerases catalyse DNA cleavage, strand passage and rejoining of the ends. Thus, although they are essential house- keeping enzymes, they are the most vulnerable targets; arrest of the reaction after the first trans-esterification step leads to breaks in DNA and cell death. Some of the successful antibacterial or anticancer drugs target the step ie arrest the reaction or stabilize the topo -DNA covalent complex. I will describe our efforts in this direction – to target DNA gyrase and also topoisomerase1 from mycobacteria. The latter, although essential, has no inhibitors described so far. The new inhibitors being characterized are also used to probe topoisomerase control of gene expression.
In the biological warfare between the organisms, a diverse set of molecules encoded by invading genomes target the above mentioned most vulnerable step of topoisomerase reaction, leading to the accumulation of double strand breaks. Bacteria, on their part appear to have developed defense strategies to protect the cells from genomic double strand breaks. I will describe a mechanism involving three distinct gyrase interacting proteins which inhibit the enzyme in vitro. However, in vivo all these topology modulators protect DNA gyrase from poisoning effect by sequestering the enzyme away from DNA.
Next, we have targeted a topology modulator protein, a nucleoid associated protein(NAP) from Mycobacterium tuberculosis to develop small molecule inhibitors by structure based design. Over expression of HU leads to alteration in the nucleoid architecture. The crystal structure of the N-terminal half of HU reveals a cleft that accommodates duplex DNA. Based on the structural feature, we have designed inhibitors which bind to the protein and affect its interaction with DNA, de-compact the nucleoid and inhibit cell growth. Chemical probing with the inhibitors reveal the importance of HU regulon in M.tuberculosis.
 Sharmila Mande, Ph.D.
Sharmila Mande, Ph.D.
Principal Scientist and Head, Bio Sciences R&D, TCS Innovation Labs, Pune
Gut microbiome and health: Moving towards the new era of translational medicine
The microbes inhabiting our body outnumber our own cells by a factor of 10. The genomes of these microbes, called the ‘second genome’ are therefore expected to have great influence on our health and well being. The emerging field of metagenomics is rapidly becoming the method of choice for studying the microbial community (called microbiomes) present in various parts of the human body. Recent studies have implicated the role of gut microbiomes in several diseases and disorders. Studies have indicated gut microbiome’s role in nutrient absorption, immuno-modulation motor-response, and other key physiological processes. However, our understanding of the role of gut microbiota in malnutrition is currently incomplete. Exploration of these aspects are likely to help in understanding the microbial basis for several physiological disorders associated with malnutrition (eg, increased susceptibility to diarrhoeal pathogens) and may finally aid in devising appropriate probiotic strategies addressing this menace. A metagenomic approach was employed for analysing the differences between gut microbial communities obtained from malnourished and healthy children. Results of the analysis using TCS’ ‘Metagenomic Analysis Platform’ were discussed in detail during my talk.

Jaipal Panga Reddy, Dulal Panda and Sanjeeva Srivastava
The rapid emergence of microbial resistance against the ever increasing number of infectious diseases has been a major hurdle in hunt for novel antibiotics and inventive targets required to combat these dreaded pathogens. Despite the discovery of synthetic and semi-synthetic drugs, infectious diseases remain a major cause of concern. The process of drug discovery started from natural products as an antibacterial drug, an old art which was widely adopted in ancient civilizations in India and China. Most of the existing antibiotics are derived from the backbone of natural compounds (Butler M S 2005). Drug discovery process from natural products to synthetic medicine has continued for thousands of years to battle with pathogenic organisms. Although synthetic drugs played a vital role as antimicrobial drugs during the last decade, the over-use of antibiotics has led to the unanticipated changes at the genomic level, resulting into emergence of antibiotic-resistant strains (Singh P et al. 2010). To combat drug-resistant strains there is a need to develop and characterize new drugs by screening natural and synthetic compounds. Curcumin is a well known natural product, with a potential to cure wide range of cancers. Apart from antitumor activity, it also has anti-inflammatory, anti-viral, anti-genotoxic, phototoxic and antimicrobial activities. The exact mechanism of action of curcumin is still obscure and further investigations are required to identify its molecular/cellular targets. Recently, it was observed that curcumin is able to perturb the FtsZ assembly dynamics and elongate the bacterial cell length by inhibiting bacterial cell division (Rai D et al. 2008).
In the present study, we aimed at deciphering the mechanism of action and molecular targets of curcumin in B. subtilis AH75 using classical two dimensional electrophoresis, 2D-difference gel electrophoresis (2DDIGE) in combination with MALDI-TOF/TOFMS. Comparative proteome analysis of control and IC50 curcumin treated B. subtilis has revealed differential expression of 48 proteins (p ≤ 0.05) in response to curcumin treatment. Further, in silico analysis has revealed the involvement of the differential expressed proteins in protein synthesis, transcription/nucleotide synthesis, stress regulation, central metabolism and amino acid metabolic process. Additionally, suppression in major central metabolic dehydrogenase such as glyceraldehyde-3-phosphate dehydrogenase 2, dihydrolipoyl dehydrogenase, malate dehydrogenase, pyruvate dehydrogenase E1 component subunit beta, 2-oxoglutarate dehydrogenase E1 component, ATP synthase epsilon chain, ATP synthase subunit beta and probable NADdependent malic enzyme 1 has been identified (Figure 1). Reduction in expression levels of major dehydrogenases indicates the disturbance in cell membrane integrity to transfer the electrons from NADH to molecular oxygen or maintain the PMF or maintain the membrane potential. Selected potential proteins obtained from proteomic analysis were validated with real-time expression analysis and metabolic assays such as resazurin assay for metabolic activity, CTC assay for respiratory activity and propidium iodide staining for membrane integrity. Findings from this study have revealed that curcumin has potential effects on multiple physiological pathways in bacteria and inhibition of the cell division machinery is one of the prime targets of this drug. Multiple proteins involved in cell division process such as GroEL, ClpC, MetK, Tuf and major dehydrogenases are significantly modulated as a consequence of the drug treatment.
 Akhilesh Pandey, Ph.D.
Akhilesh Pandey, Ph.D.
Professor, Johns Hopkins University School of Medicine, Baltimore, USA
A draft map of the human proteome
We have generated a draft map of the human proteome through a systematic and comprehensive analysis of normal human adult tissues, fetal tissues and hematopoietic cells as an India-US initiative. This unique dataset was generated from 30 histologically normal adult tissues, fetal tissues and purified primary hematopoietic cells that were analyzed at high resolution in the MS mode and by HCD fragmentation in the MS/MS mode on LTQ-Orbitrap Velos/Elite mass spectrometers. This dataset was searched against a 6-frame translation of the human genome and RNA-Seq transcripts in addition to standard protein databases. In addition to confirming a large majority (>16,000) of the annotated protein-coding genes in humans, we obtained novel information at multiple levels: novel protein-coding genes, unannotated exons, novel splice sites, proof of translation of pseudogenes (i.e. genes incorrectly annotated as pseudogenes), fused genes, SNPs encoded in proteins and novel N-termini to name a few. Many proteins identified in this study were identified by proteomic methods for the first time (e.g. hypothetical proteins or proteins annotated based solely on their chromosomal location). We have generated a catalog of proteins that show a more tissue-restricted pattern of expression, which should serve as the basis for pursuing biomarkers for diseases pertaining to specific organs. This study also provides one of the largest sets of proteotypic peptides for use in developing MRM assays for human proteins. Identification of several novel protein-coding regions in the human genome underscores the importance of systematic characterization of the human proteome and accurate annotation of protein-coding genes. This comprehensive dataset will complement other global HUPO initiatives using antibody-based as well as MRM mass spectrometry-based strategies. Finally, we believe that this dataset will become a reference set for use as a spectral library as well as for interesting interrogations pertaining to biomedical as well as bioinformatics questions.


Sukhithasri V, Nisha N, Vivek V and Raja Biswas
The host innate immune system acts as the first line of defense against invading pathogens. During an infection, the host innate immune cells recognize unique conserved molecules on the pathogen known as Pathogen Associated Molecular Patterns (PAMPs). This recognition of PAMPs helps the host mount an innate immune response leading to the production of cytokines (Akira et al. 2006). Peptidoglycan, one of the most conserved and essential component of the bacterial cell wall is one such PAMP. Peptidoglycan is known to have potent proinflammatory properties (Gust et al. 2007). Host recognize peptidoglycan using Nucleotide oligomerization domain proteins (NODs). This recognition of peptidoglycan activates the NODs and triggers downstream signaling leading to the nuclear translocation of NF-κB and production of cytokines (McDonald et al. 2005). Pathogenic bacteria modify their peptidoglycan as a strategy to evade innate immune recognition, which helps it to establish infection in the host. These peptidoglycan modifications include O-acetylation and N-glycolylation of muramic acid and N-deacetylation of N-acetylglucosamine (Davis et al. 2011). Modification of mycobacterial peptidoglycan by N-glycolylation prevents the catalytic activity of lysozyme (Raymond et al. 2005). Additionally, mycobacterial peptidoglycan is modified by amidation for unknown reasons.
Here, we have investigated the role of amidated peptidoglycan in Mycobacterium sp in modulating the innate immune response. We isolated amidated peptidoglycan from Mycobacterium sp and non-amidated peptidoglycan from Escherichia coli. We made a comparative analysis of the cytokine response produced on stimulation of innate immune cells by peptidoglycan from E. Coli and Mycobacterium sp. Macrophages and whole blood were treated with peptidoglycan and the cytokines secreted into spent medium and plasma respectively were analyzed using ELISA. Our results show that peptidoglycan from Mycobacterium sp is less effective in stimulating innate immune cells to produce cytokines. This intrinsic modulation of the cytokine response suggests that mycobacteria modify their peptidoglycan by amidation to evade innate immune response.

Tejaswini Subbannayya, Nandini A. Sahasrabuddhe, Arivusudar Marimuthu, Santosh Renuse, Gajanan Sathe, Srinivas M. Srikanth, Mustafa A. Barbhuiya, Bipin Nair, Juan Carlos Roa, Rafael Guerrero-Preston, H. C. Harsha, David Sidransky, Akhilesh Pandey, T. S. Keshava Prasad and Aditi Chatterjee
Proteomic profiling of gallbladder cancer secretome – a source for circulatory biomarker discovery
Gallbladder cancer (GBC) is the fifth most common cancer of the gastrointestinal tract and one of the common malignancies that occur in the biliary tract (Misra et al. 2006; Lazcano-Ponce et al. 2001). It has a poor prognosis with survival of less than 5 years in 90% of the cases (Misra et al. 2003). The etiology is ill-defined. Several risk factors have been reported including cholelithiasis, obesity, female gender and exposure to carcinogens (Eslick 2010; Kumar et al. 2006). Poor prognosis in GBC is mainly due to late presentation of the disease and lack of reliable biomarkers for early diagnosis. This emphasizes the need to identify and characterize cancer biomarkers to aid in the diagnosis and prognosis of GBC. Secreted proteins are an important class of molecules which can be detected in body fluids and has been targeted for biomarker discovery. There are challenges faced in the proteomic interrogation of body fluids especially plasma such as low abundance of tumor secreted proteins, high complexity and high abundance of other proteins that are not released by the tumor cells (Tonack et al. 2009). Profiling of conditioned media from the cancer cell lines can be used as an alternate means to identify secreted proteins from tumor cells (Kashyap et al. 2010; Marimuthu et al. 2012). We analyzed the invasive property of 7 GBC cell lines (SNU-308, G-415, GB-d1, TGBC2TKB, TGBC24TKB, OCUG-1 and NOZ). Four cell lines were selected for analysis of the cancer secretome based on the invasive property of the cells. We employed isobaric tags for relative and absolute quantitation (iTRAQ) labeling technology coupled with high resolution mass spectrometry to identify and characterize secretome from the panel of 4GBC cancer cells mentioned above. In total, we have identified around 2,000 proteins of which 175 were secreted at differential abundance across all the four cell lines. This secretome analysis will act as a reservoir of candidate biomarkers. Currently, we are investigating and validating these candidate markers from GBC cell secretome. Through this study, we have shown mass spectrometry-based quantitative proteomic analysis as a robust approach to investigate secreted proteins in cancer cells.