

 Pradip K. Bhatnagar, Ph.D.
Pradip K. Bhatnagar, Ph.D.
Former President & Head, Daiichi Sankyo Life Science Research Centre, India
Strategies for Diseases/Target Selection for Drug Discovery and a Multi-Targeted Approach to Metabolic Disorder
Drug discovery and development is a high risk and expensive undertaking. Although, technologies, such as, bioinformatics, genomics, high throughput screening and computer-aided design have helped identify targets, biomarkers, lead candidates and reduced the time required for advancing an idea from bench to clinic, but it still takes 10-12 years and costs approximately one billion dollars to bring a drug to market globally. Therefore, it is imperative that the strategies to reduce the risk and increase efficiency are carefully selected. In this presentation I would discuss strategies for selecting potential diseases, targets and provide an example of multi-targeted approach to metabolic disorder.
 Sanjeeva Srivastava, Ph.D.
Sanjeeva Srivastava, Ph.D.
Assistant Professor, Proteomics Lab, IIT-Bombay, India
Identification of Potential Early Diagnostic Biomarkers for Gliomas and Various Infectious Diseases using Proteomic Technologies
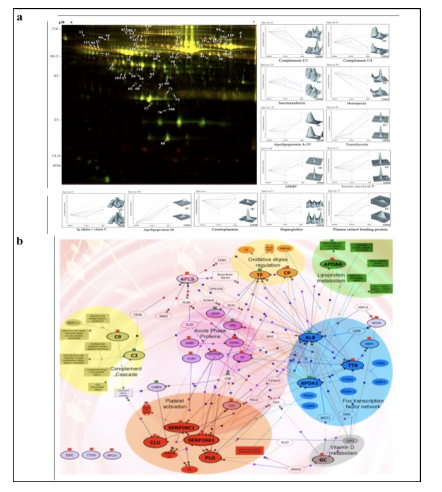
The spectacular advancements achieved in the field of proteomics research during the last decade have propelled the growth of proteomics for clinical research. Recently, comprehensive proteomic analyses of different biological samples such as serum or plasma, tissue, CSF, urine, saliva etc. have attracted considerable attention for the identification of protein biomarkers as early detection surrogates for diseases (Ray et al., 2011). Biomarkers are biomolecules that can be used for early disease detection, differentiation between closely related diseases with similar clinical manifestations as well as aid in scrutinizing disease progression. Our research group is performing in-depth analysis of alteration in human proteome in different types of brain tumors and various pathogenic infections to obtain mechanistic insight about the disease pathogenesis and host immune responses, and identification of surrogate protein markers for these fatal human diseases.
Applying 2D-DIGE in combination with MALDI-TOF/TOF MS we have analyzed the serum and tissue proteome profiles of glioblastoma multiforme; the most common and lethal adult malignant brain tumor (Gollapalli et al., 2012) (Figure 1). Results obtained were validated by employing different immunoassay-based approaches. In serum proteomic analysis we have identified some interesting proteins like haptoglobin, ceruloplasmin, vitamin-D binding protein etc. Moreover, proteomic analysis of different grades (grade-I to IV) of gliomas and normal brain tissue was performed and differential expressions of quite a few proteins such as SIRT2, GFAP, SOD, CDC42 have been identified, which have significant correlation with the tumor growth. While proteomic analysis of cerebrospinal fluid from low grade (grade I & II) vs. high grade (grade III & IV) gliomas revealed modulation of CSF levels of apolipoprotein E, dickkopf related protein 3, vitamin D binding protein and albumin in high grade gliomas. The prospective candidates identified in our studies provide a mechanistic insight of glioma pathogenesis and identification of potential biomarkers. We are also studying the role of JAK/STAT interactome and therapeutic potential of STAT3 inhibitors in gliomas using proteomics approach. Several candidates of the JAK/STAT interactome were identified with altered expression and a significant correlation was observed between STAT3 and PDK1 transcript expression level.
We have also investigated the changes in human serum proteome in different infectious diseases including falciparum and vivax malaria (Ray et al., 2012a; Ray et al., 2012b), dengue (Ray et al., 2012c) and leptospirosis (Srivastava et al., 2012). Although, quite a few serum proteins were found to be commonly altered in different infectious diseases and might be a consequence of inflammation mediated acute phase response signaling, uniquely modulated candidates were identified in each pathogenic infection indicating the some inimitable responses. Further, a panel of identified proteins consists of six candidates; serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I was used to build statistical sample class prediction models employing PLSDA and other classification methods to predict the clinical phenotypic classes and 91.37% overall prediction accuracy was achieved (Figure 2). ROC curve analysis was carried out to evaluate the individual performance of classifier proteins. The excellent discrimination among the different disease groups on the basis of differentially expressed proteins demonstrates the potential diagnostic implications of this analytical approach.
Keywords: Diagnostic biomarkers, Gliomas, Infectious Diseases, Proteomics, Serum proteome
Acknowledgments: This disease biomarker discovery research was supported by Department of Biotechnology, India grant (No. BT/PR14359/MED/30/916/2010), Board of Research in Nuclear Sciences (BRNS) DAE young scientist award (2009/20/37/4/BRNS) and a startup grant 09IRCC007 from the IIT Bombay. The active support from Advanced Center for Treatment Research and Education in Cancer (ACTREC), Tata Memorial Hospital (TMH), and Seth GS Medical College and KEM Hospital Mumbai, India in clinical sample collection process is gratefully acknowledged.
References :
- Ray S, Reddy PJ, Jain R, Gollapalli K. Moiyadi A, Srivastava S. Proteomic technologies for the identification of disease biomarkers in serum: advances and challenges ahead. Proteomics 11: 2139-61, 2011.
- Gollapalli K, Ray S, Srivastava R, Renu D, Singh P, Dhali S, Dikshit JB, Srikanth R, Moiyadi A, Srivastava S. Investigation of serum proteome alterations in human glioblastoma multiforme. Proteomics 12(14): 2378-90, 2012.
- Ray S, Renu D, Srivastava R, Gollapalli K, Taur S, Jhaveri T, Dhali S, Chennareddy S, Potla A, Dikshit JB, Srikanth R, Gogtay N, Thatte U, Patankar S, Srivastava S. Proteomic investigation of falciparum and vivax malaria for identification of surrogate protein markers. PLoS One 7(8): e41751, 2012a.
- Ray S, Kamath KS, Srivastava R, Raghu D, Gollapalli K, Jain R, Gupta SV, Ray S, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Patankar S, Srivastava S. Serum proteome analysis of vivax malaria: An insight into the disease pathogenesis and host immune response. J Proteomics 75(10): 3063-80, 2012b.
- Srivastava R, Ray S, Vaibhav V, Gollapalli K, Jhaveri T, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Srivastava S. Serum profiling of leptospirosis patients to investigate proteomic alterations. J Proteomics 76: 56-68, 2012.
- Ray S, Srivastava R, Tripathi K, Vaibhav V, Srivastava S. Serum proteome changes in dengue virus-infected patients from a dengue-endemic area of India: towards new molecular targets? OMICS 16(10): 527-36, 2012c.
* Correspondence: Dr. Sanjeeva Srivastava, Department of Biosciences and Bioengineering, IIT Bombay, Mumbai 400 076, India: E-mail: sanjeeva@iitb.ac.in; Phone: +91-22-2576-7779, Fax: +91-22-2572-3480
![Figure 2 (a) Western blot analysis of haptoglobin (HP), serum amyloid A (SAA), and clusterin (CLU) from serum samples of healthy control (HC) [n = 12], falciparum malaria (FM) [n = 12], vivax malaria (VM) [n = 12], Leptospirosis (Lep) [n = 6], dengue fever [DF] [n = 6] and non infectious disease control (NIDC:GBM) [n = 12]. Representative blots of the target proteins are depicted along with their respective relative abundance volumes (volume X 104). All the data are represented as mean ± SE. (b) Discrimination of malaria from dengue, leptospirosis and GBM using PLS-DA analysis. PLS-DA scores Plot for FM (blue spheres, n = 8), VM (green spheres, n = 8), DF (red spheres, n = 6), Lep (grey spheres, n = 6) and GBM (brown spheres, n = 8) samples based on 6 differentially expressed proteins (serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I) identified using DIGE. The axes of the plot indicate PLSDA latent variables t0-t2.](http://www.amritabioquest.org/conference/2013/wp-content/uploads/sites/2/2015/02/sanjeeva-2.jpg)


 Kal Ramnarayan, Ph.D.
Kal Ramnarayan, Ph.D.
Co-founder President & Chief Scientific Officer, Sapient Discovery, San Diego, CA, USA
A cost-effective approach to Protein Structure-guided Drug Discovery: Aided by Bioinformatics, Chemoinformatics and computational chemistry
With the mapping of the human genome completed almost a decade ago, efforts are still underway to understand the gene products (i.e., proteins) in the human biological and disease pathways. Deciphering such information is very important for the discovery and development of small molecule drugs as well as protein therapeutics for various human diseases for which no cure exists. As an example, with more than 500 members, the kinase family of protein targets continues to be an important and attractive class for drug discovery. While how many of the members in this family are actually druggable is still to be established, there are several ongoing efforts on this class of proteins across a broad spectrum of disease categories. Even though in general the protein structural topology might looks similar, there are issues with respect selectivity of identified small molecule inhibitors when, the lead molecule discovery is carried out at the ATP binding site. As an added complexity, allosteric modulators are needed for some of the members, but the actual site for such modulation on the protein target can not resolved with uncertainty. In this presentation we will describe a bioinformatics and computational based platform for small molecule discovery for protein targets that are involved in protein-protein interactions as well as targets like kinases and phosphatases. We will describe a computational approach in which we have used an informatics based platform with several hundred kinases to sort through in silico and identify inhibitors that are likely to be highly selective in the lead generation phase. We will discuss the implication of this approach on the drug discovery of the kinase and phosphatase classes in general and independent of the disease category.
 V. Nagaraja Ph.D.
V. Nagaraja Ph.D.
Professor, Indian Institute of Science, Bengaluru, India
Perturbation of DNA topology in mycobacteria
To maintain the topological homeostasis of the genome in the cell, DNA topoisomerases catalyse DNA cleavage, strand passage and rejoining of the ends. Thus, although they are essential house- keeping enzymes, they are the most vulnerable targets; arrest of the reaction after the first trans-esterification step leads to breaks in DNA and cell death. Some of the successful antibacterial or anticancer drugs target the step ie arrest the reaction or stabilize the topo -DNA covalent complex. I will describe our efforts in this direction – to target DNA gyrase and also topoisomerase1 from mycobacteria. The latter, although essential, has no inhibitors described so far. The new inhibitors being characterized are also used to probe topoisomerase control of gene expression.
In the biological warfare between the organisms, a diverse set of molecules encoded by invading genomes target the above mentioned most vulnerable step of topoisomerase reaction, leading to the accumulation of double strand breaks. Bacteria, on their part appear to have developed defense strategies to protect the cells from genomic double strand breaks. I will describe a mechanism involving three distinct gyrase interacting proteins which inhibit the enzyme in vitro. However, in vivo all these topology modulators protect DNA gyrase from poisoning effect by sequestering the enzyme away from DNA.
Next, we have targeted a topology modulator protein, a nucleoid associated protein(NAP) from Mycobacterium tuberculosis to develop small molecule inhibitors by structure based design. Over expression of HU leads to alteration in the nucleoid architecture. The crystal structure of the N-terminal half of HU reveals a cleft that accommodates duplex DNA. Based on the structural feature, we have designed inhibitors which bind to the protein and affect its interaction with DNA, de-compact the nucleoid and inhibit cell growth. Chemical probing with the inhibitors reveal the importance of HU regulon in M.tuberculosis.
 Karmeshu, Ph.D.
Karmeshu, Ph.D.
Dean & Professor, School of Computer & Systems Sciences & School of Computational & Integrative Sciences, Jawaharlal Nehru University, India.
Interspike Interval Distribution of Neuronal Model with distributed delay: Emergence of unimodal, bimodal and Power law
The study of interspike interval distribution of spiking neurons is a key issue in the field of computational neuroscience. A wide range of spiking patterns display unimodal, bimodal ISI patterns including power law behavior. A challenging problem is to understand the biophysical mechanism which can generate the empirically observed patterns. A neuronal model with distributed delay (NMDD) is proposed and is formulated as an integro-stochastic differential equation which corresponds to a non-markovian process. The widely studied IF and LIF models become special cases of this model. The NMDD brings out some interesting features when excitatory rates are close to inhibitory rates rendering the drift close to zero. It is interesting that NMDD model with gamma type memory kernel can also account for bimodal ISI pattern. The mean delay of the memory kernels plays a significant role in bringing out the transition from unimodal to bimodal ISI distribution. It is interesting to note that when a collection of neurons group together and fire together, the ISI distribution exhibits power law.
 Lalitha Subramanian, Ph.D.
Lalitha Subramanian, Ph.D.
Chief Scientific Officer & VP, Services at Scienomics, USA
Nanoscale Simulations – Tackling Form and Formulation Challenges in Drug Development and Drug Delivery
Lalitha Subramanian, Dora Spyriouni, Andreas Bick, Sabine Schweizer, and Xenophon Krokidis Scienomics
The discovery of a compound which is potent in activity against a target is a major milestone in Pharmaceutical and Biotech industry. However, a potent compound is only effective as a therapeutic agent when it can be administered such that the optimal quantity is transported to the site of action at an optimal rate. The active pharmaceutical ingredient (API) has to be tested for its physicochemical properties before the appropriate dosage form and formulation can be designed. Some of the commonly evaluated parameters are crystal forms and polymorphs, solubility, dissolution behavior, stability, partition coefficient, water sorption behavior, surface properties, particle size and shape, etc. Pharmaceutical development teams face the challenge of quickly and efficiently determining a number of properties with small quantities of the expensive candidate compounds. Recently the trend has been to screen these properties as early as possible and often the candidate compounds are not available in sufficient quantities. Increasingly, these teams are leveraging nanoscale simulations similar to those employed by drug discovery teams for several decades. Nanoscale simulations are used to predict the behavior using very little experimental data and only if this is promising further experiments are done. Another aspect where nanoscale simulations are being used in drug development and drug delivery is to get insights into the behavior of the system so that process failures can be remediated and formulation performance can be improved. Thus, the predictive screening and the in-depth understanding leads to experimental efficiency resulting in far-reaching business impacts.
With specific examples, this talk will focus on the different types of nanoscale simulations used to predict properties of the API in excipients and also provide insight into system behavior as a function of shelf life, temperature, mechanical stress, etc.

The global healthcare scene of which the pharmaceutical industry and its products are integral components is today at the cross roads. The high and unaffordable costs of drug research with estimates of over 1 billion dollars for every new drug discovered and developed, the very low success rates, the high degree of obsolescence due to undesirable adverse drug reactions, the decline in the development pipeline of new drugs, patent expiries leading to generic competition and the public’s disillusionment with use of chemicals for human consumption as drugs have all significantly contributed to the problems of this lifeline industry. The strategy adopted by the large R&D based Corporations to get bigger and bigger through mergers and acquisitions to improve cost-effectiveness and productivity of R&D has so far not worked effectively. Consequently, one of the recent trends in healthcare, articulated by many experts is to look for alternate or even complementary approaches to reduce the impact of rising costs of drugs on healthcare. Various new strategies for drug discovery such as the use of Natural Products especially medicinal plants are being actively pursued by healthcare planners and providers. Side by side, traditional systems of medicine whether from the oriental countries or the western nations are also having a serious relook to understand their usefulness in healthcare. To achieve its legitimate position in the healthcare scenario, it is essential to scientifically validate their claimed utility through appropriate and systematic research efforts including pre-clinical and clinical studies. In addition to their own use as medicines, knowledge on the Indian Traditional Medicines can be used as a platform for new drug discovery. The huge potential for carrying out systematic R&D programs for new Drug Discovery based on natural products and possible strategies to realise them in the coming decades will be explained in this presentation.

 Ramani A. Aiyer, Ph.D., MBA
Ramani A. Aiyer, Ph.D., MBA
Principal, Shasta BioVentures, San Jose, CA, USA
New Drug R&D in India: Challenges & Opportunities
New drug discovery and development has become a global endeavor, with Western big pharmaceutical companies farming out more and more chemistry and biology research to Asia, particularly India and China. During the last decade, several Indian pharmaceutical companies have embarked on ambitious R&D programs, with slow but steady progress in developing new chemical / molecular entities. The Indian government has also made a strong commitment to promote innovation and entrepreneurship in the biotechnology sector. The first part of the talk will focus on a case study showing the entire process of discovery and development of a new drug recently launched for Rheumatoid Arthritis. We will then address the challenges of conducting innovative R&D in India and actions necessary to overcome them. The second part of the talk will make the case for developing Ayurvedic drug formulations for the Western / Global markets, again using the example of Rheumatoid Arthritis (Aamavaata). Ayurveda takes a holistic approach to disease diagnosis and therapy based on interactions among body type (prakriti), tri-doshas (three body humors), sapta-dhatus (seven tissues) and malas (excretions). The drugs prescribed are usually herbo-mineral formulations comprising multiple medicinal plants and / or metals. The manufacturing processes date back to Ayurvedic texts several thousand years old, and are compiled in the Ayurvedic Pharmacopeia. Also, the treatment modalities and drug formulations are “personalized” to fit different patient types, based on the holistic diagnoses mentioned earlier. There is a tremendous need to establish a sound basis for Ayurvedic drug discovery R&D for the modern world. We must find a scientific and ethical way to leverage the vast body of anecdotal and possibly retrospective data on patients undergoing Ayurvedic treatment. Combined with in vitro and in vivo biological data on Ayurvedic herbo-mineral formulations, the adoption of stringent manufacturing practices, and designing sound clinical trials to establish the safety and efficacy, India has a golden opportunity to expand the reach of Ayurvedic drugs into Western / Global medical practice.


Sukhithasri V, Nisha N, Vivek V and Raja Biswas
The host innate immune system acts as the first line of defense against invading pathogens. During an infection, the host innate immune cells recognize unique conserved molecules on the pathogen known as Pathogen Associated Molecular Patterns (PAMPs). This recognition of PAMPs helps the host mount an innate immune response leading to the production of cytokines (Akira et al. 2006). Peptidoglycan, one of the most conserved and essential component of the bacterial cell wall is one such PAMP. Peptidoglycan is known to have potent proinflammatory properties (Gust et al. 2007). Host recognize peptidoglycan using Nucleotide oligomerization domain proteins (NODs). This recognition of peptidoglycan activates the NODs and triggers downstream signaling leading to the nuclear translocation of NF-κB and production of cytokines (McDonald et al. 2005). Pathogenic bacteria modify their peptidoglycan as a strategy to evade innate immune recognition, which helps it to establish infection in the host. These peptidoglycan modifications include O-acetylation and N-glycolylation of muramic acid and N-deacetylation of N-acetylglucosamine (Davis et al. 2011). Modification of mycobacterial peptidoglycan by N-glycolylation prevents the catalytic activity of lysozyme (Raymond et al. 2005). Additionally, mycobacterial peptidoglycan is modified by amidation for unknown reasons.
Here, we have investigated the role of amidated peptidoglycan in Mycobacterium sp in modulating the innate immune response. We isolated amidated peptidoglycan from Mycobacterium sp and non-amidated peptidoglycan from Escherichia coli. We made a comparative analysis of the cytokine response produced on stimulation of innate immune cells by peptidoglycan from E. Coli and Mycobacterium sp. Macrophages and whole blood were treated with peptidoglycan and the cytokines secreted into spent medium and plasma respectively were analyzed using ELISA. Our results show that peptidoglycan from Mycobacterium sp is less effective in stimulating innate immune cells to produce cytokines. This intrinsic modulation of the cytokine response suggests that mycobacteria modify their peptidoglycan by amidation to evade innate immune response.