Vural Özdemir Ph.D.
Sanjeeva Srivastava Ph.D.
 Rohit Manchanda, Ph.D.
Rohit Manchanda, Ph.D.
Professor, Biomedical Engineering Group, IIT-Bombay, India
Modelling the syncytial organization and neural control of smooth muscle: insights into autonomic physiology and pharmacology
We have been studying computationally the syncytial organization and neural control of smooth muscle in order to help explain certain puzzling findings thrown up by experimental work. This relates in particular to electrical signals generated in smooth muscles, such as synaptic potentials and spikes, and how these are explicable only if three-dimensional syncytial biophysics are taken fully into account. In this talk, I shall provide an illustration of outcomes and insights gleaned from such an approach. I shall first describe our work on the mammalian vas deferens, in which an analysis of the effects of syncytial coupling led us to conclude that the experimental effects of a presumptive gap junction uncoupler, heptanol, on synaptic potentials were incompatible with gap junctional block and could best be explained by a heptanol-induced inhibition of neurotransmitter release, thus compelling a reinterpretation of the mechanism of action of this agent. I shall outline the various lines of evidence, based on indices of syncytial function, that we adduced in order to reach this conclusion. We have now moved on to our current focus on urinary bladder biophysics, where the questions we aim to address are to do with mechanisms of spike generation. Smooth muscle cells in the bladder exhibit spontaneous spiking and spikes occur in a variety of distinct shapes, making their generation problematic to explain. We believe that the variety in shapes may owe less to intrinsic differences in spike mechanism (i.e., in the complement of ion channels participating in spike production) and more to features imposed by syncytial biophysics. We focus especially on the modulation of spike shape in a 3-D coupled network by such factors as innervation pattern, propagation in a syncytium, electrically finite bundles within and between which the spikes spread, and some degree of pacemaker activity by a sub-population of the cells. I shall report two streams of work that we have done, and the tentative conclusions these have enabled us to reach: (a) using the NEURON environment, to construct the smooth muscle syncytium and endow it with synaptic drive, and (b) using signal-processing approaches, towards sorting and classifying the experimentally recorded spikes.


 Sanjeeva Srivastava, Ph.D.
Sanjeeva Srivastava, Ph.D.
Assistant Professor, Proteomics Lab, IIT-Bombay, India
Identification of Potential Early Diagnostic Biomarkers for Gliomas and Various Infectious Diseases using Proteomic Technologies
The spectacular advancements achieved in the field of proteomics research during the last decade have propelled the growth of proteomics for clinical research. Recently, comprehensive proteomic analyses of different biological samples such as serum or plasma, tissue, CSF, urine, saliva etc. have attracted considerable attention for the identification of protein biomarkers as early detection surrogates for diseases (Ray et al., 2011). Biomarkers are biomolecules that can be used for early disease detection, differentiation between closely related diseases with similar clinical manifestations as well as aid in scrutinizing disease progression. Our research group is performing in-depth analysis of alteration in human proteome in different types of brain tumors and various pathogenic infections to obtain mechanistic insight about the disease pathogenesis and host immune responses, and identification of surrogate protein markers for these fatal human diseases.
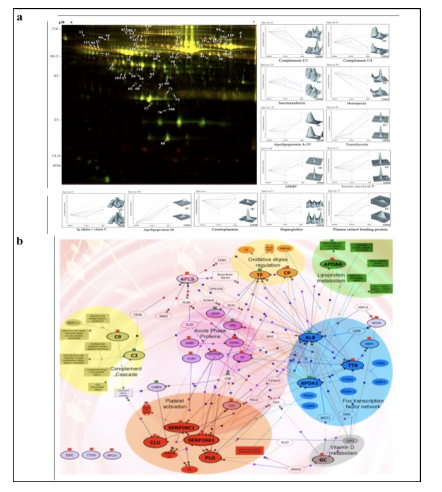
Applying 2D-DIGE in combination with MALDI-TOF/TOF MS we have analyzed the serum and tissue proteome profiles of glioblastoma multiforme; the most common and lethal adult malignant brain tumor (Gollapalli et al., 2012) (Figure 1). Results obtained were validated by employing different immunoassay-based approaches. In serum proteomic analysis we have identified some interesting proteins like haptoglobin, ceruloplasmin, vitamin-D binding protein etc. Moreover, proteomic analysis of different grades (grade-I to IV) of gliomas and normal brain tissue was performed and differential expressions of quite a few proteins such as SIRT2, GFAP, SOD, CDC42 have been identified, which have significant correlation with the tumor growth. While proteomic analysis of cerebrospinal fluid from low grade (grade I & II) vs. high grade (grade III & IV) gliomas revealed modulation of CSF levels of apolipoprotein E, dickkopf related protein 3, vitamin D binding protein and albumin in high grade gliomas. The prospective candidates identified in our studies provide a mechanistic insight of glioma pathogenesis and identification of potential biomarkers. We are also studying the role of JAK/STAT interactome and therapeutic potential of STAT3 inhibitors in gliomas using proteomics approach. Several candidates of the JAK/STAT interactome were identified with altered expression and a significant correlation was observed between STAT3 and PDK1 transcript expression level.
We have also investigated the changes in human serum proteome in different infectious diseases including falciparum and vivax malaria (Ray et al., 2012a; Ray et al., 2012b), dengue (Ray et al., 2012c) and leptospirosis (Srivastava et al., 2012). Although, quite a few serum proteins were found to be commonly altered in different infectious diseases and might be a consequence of inflammation mediated acute phase response signaling, uniquely modulated candidates were identified in each pathogenic infection indicating the some inimitable responses. Further, a panel of identified proteins consists of six candidates; serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I was used to build statistical sample class prediction models employing PLSDA and other classification methods to predict the clinical phenotypic classes and 91.37% overall prediction accuracy was achieved (Figure 2). ROC curve analysis was carried out to evaluate the individual performance of classifier proteins. The excellent discrimination among the different disease groups on the basis of differentially expressed proteins demonstrates the potential diagnostic implications of this analytical approach.
Keywords: Diagnostic biomarkers, Gliomas, Infectious Diseases, Proteomics, Serum proteome
Acknowledgments: This disease biomarker discovery research was supported by Department of Biotechnology, India grant (No. BT/PR14359/MED/30/916/2010), Board of Research in Nuclear Sciences (BRNS) DAE young scientist award (2009/20/37/4/BRNS) and a startup grant 09IRCC007 from the IIT Bombay. The active support from Advanced Center for Treatment Research and Education in Cancer (ACTREC), Tata Memorial Hospital (TMH), and Seth GS Medical College and KEM Hospital Mumbai, India in clinical sample collection process is gratefully acknowledged.
References :
- Ray S, Reddy PJ, Jain R, Gollapalli K. Moiyadi A, Srivastava S. Proteomic technologies for the identification of disease biomarkers in serum: advances and challenges ahead. Proteomics 11: 2139-61, 2011.
- Gollapalli K, Ray S, Srivastava R, Renu D, Singh P, Dhali S, Dikshit JB, Srikanth R, Moiyadi A, Srivastava S. Investigation of serum proteome alterations in human glioblastoma multiforme. Proteomics 12(14): 2378-90, 2012.
- Ray S, Renu D, Srivastava R, Gollapalli K, Taur S, Jhaveri T, Dhali S, Chennareddy S, Potla A, Dikshit JB, Srikanth R, Gogtay N, Thatte U, Patankar S, Srivastava S. Proteomic investigation of falciparum and vivax malaria for identification of surrogate protein markers. PLoS One 7(8): e41751, 2012a.
- Ray S, Kamath KS, Srivastava R, Raghu D, Gollapalli K, Jain R, Gupta SV, Ray S, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Patankar S, Srivastava S. Serum proteome analysis of vivax malaria: An insight into the disease pathogenesis and host immune response. J Proteomics 75(10): 3063-80, 2012b.
- Srivastava R, Ray S, Vaibhav V, Gollapalli K, Jhaveri T, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Srivastava S. Serum profiling of leptospirosis patients to investigate proteomic alterations. J Proteomics 76: 56-68, 2012.
- Ray S, Srivastava R, Tripathi K, Vaibhav V, Srivastava S. Serum proteome changes in dengue virus-infected patients from a dengue-endemic area of India: towards new molecular targets? OMICS 16(10): 527-36, 2012c.
* Correspondence: Dr. Sanjeeva Srivastava, Department of Biosciences and Bioengineering, IIT Bombay, Mumbai 400 076, India: E-mail: sanjeeva@iitb.ac.in; Phone: +91-22-2576-7779, Fax: +91-22-2572-3480
![Figure 2 (a) Western blot analysis of haptoglobin (HP), serum amyloid A (SAA), and clusterin (CLU) from serum samples of healthy control (HC) [n = 12], falciparum malaria (FM) [n = 12], vivax malaria (VM) [n = 12], Leptospirosis (Lep) [n = 6], dengue fever [DF] [n = 6] and non infectious disease control (NIDC:GBM) [n = 12]. Representative blots of the target proteins are depicted along with their respective relative abundance volumes (volume X 104). All the data are represented as mean ± SE. (b) Discrimination of malaria from dengue, leptospirosis and GBM using PLS-DA analysis. PLS-DA scores Plot for FM (blue spheres, n = 8), VM (green spheres, n = 8), DF (red spheres, n = 6), Lep (grey spheres, n = 6) and GBM (brown spheres, n = 8) samples based on 6 differentially expressed proteins (serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I) identified using DIGE. The axes of the plot indicate PLSDA latent variables t0-t2.](http://www.amritabioquest.org/conference/2013/wp-content/uploads/sites/2/2015/02/sanjeeva-2.jpg)


 Nader Pourmand, Ph.D.
Nader Pourmand, Ph.D.
Director, UCSC Genome Technology Center,University of California, Santa Cruz
Biosensor and Single Cell Manipulation using Nanopipettes
Approaching sub-cellular biological problems from an engineering perspective begs for the incorporation of electronic readouts. With their high sensitivity and low invasiveness, nanotechnology-based tools hold great promise for biochemical sensing and single-cell manipulation. During my talk I will discuss the incorporation of electrical measurements into nanopipette technology and present results showing the rapid and reversible response of these subcellular sensors to different analytes such as antigens, ions and carbohydrates. In addition, I will present the development of a single-cell manipulation platform that uses a nanopipette in a scanning ion-conductive microscopy technique. We use this newly developed technology to position the nanopipette with nanoscale precision, and to inject and/or aspirate a minute amount of material to and from individual cells or organelle without comprising cell viability. Furthermore, if time permits, I will show our strategy for a new, single-cell DNA/ RNA sequencing technology that will potentially use nanopipette technology to analyze the minute amount of aspirated cellular material.
 Srisairam Achuthan, Ph.D.
Srisairam Achuthan, Ph.D.
Senior Scientific Programmer, Research Informatics Division, Department of Information Sciences, City of Hope, CA, USA
Applying Machine learning for Automated Identification of Patient Cohorts
Srisairam Achuthan, Mike Chang, Ajay Shah, Joyce Niland
Patient cohorts for a clinical study are typically identified based on specific selection criteria. In most cases considerable time and effort are spent in finding the most relevant criteria that could potentially lead to a successful study. For complex diseases, this process can be more difficult and error prone since relevant features may not be easily identifiable. Additionally, the information captured in clinical notes is in non-coded text format. Our goal is to discover patterns within the coded and non-coded fields and thereby reveal complex relationships between clinical characteristics across different patients that would be difficult to accomplish manually. Towards this, we have applied machine learning techniques such as artificial neural networks and decision trees to determine patients sharing similar characteristics from available medical records. For this proof of concept study, we used coded and non-coded (i.e., clinical notes) patient data from a clinical database. Coded clinical information such as diagnoses, labs, medications and demographics recorded within the database were pooled together with non-coded information from clinical notes including, smoking status, life style (active / inactive) status derived from clinical notes. The non-coded textual information was identified and interpreted using a Natural Language Processing (NLP) tool I2E from Linguamatics.

Aswath Balakrishnan, Kapaettu Satyamoorthy and Manjunath B Joshi
Introduction
Insulin resistance is a hall mark of metabolic disorders such as diabetes. Reduced insulin response in vasculature leads to disruption of IR/Akt/eNOS signaling pathway resulting in vasoconstriction and subsequently to cardiovascular diseases. Recent studies have demonstrated that inflammatory regulator interleukin-6 (IL-6), as one of the potential mediators that can link chronic inflammation with insulin resistance. Accumulating evidences suggest a significant role of epigenetic mechanisms such as DNA methylation in progression of metabolic disorders. Hence the present study aimed to understand the role of epigenetic mechanisms involved during IL-6 induced vascular insulin resistance and its consequences in cardiovascular diseases.
Materials and Methods
Human umbilical vein endothelial cells (HUVEC) and Human dermal microvascular endothelial cells (HDMEC) were used for this study. Endothelial cells were treated in presence or absence of IL-6 (20ng/ml) for 36 hours and followed by insulin (100nM) stimulation for 15 minutes. Using immunoblotting, cell lysates were stained for phosphor- and total Akt levels to measure insulin resistance. To investigate changes in DNA methylation, cells were treated with or without neutrophil conditioned medium (NCM) as a physiological source of inflammation or IL-6 (at various concentrations) for 36 hours. Genomic DNA was processed for HPLC analysis for methyl cytosine content and cell lysates were analyzed for DNMT1 (DNA (cytosine-5)-methyltransferase 1) and DNMT3A (DNA (cytosine-5)-methyltransferase 3A) levels using immunoblotting.
Results
Endothelial cells stimulated with insulin exhibited an increase in phosphorylation of Aktser 473 in serum free conditions but such insulin response was not observed in cells treated with IL-6, suggesting chronic exposure of endothelial cells to IL-6 leads to insulin resistance. HPLC analysis for global DNA methylation resulted in decreased levels of 5-methyl cytosine in cells treated with pro-inflammatory molecules (both by NCM and IL-6) as compared to untreated controls. Subsequently, analysis in cells treated with IL-6 showed a significant decrease in DNMT1 levels but not in DNMT3A. Other pro-inflammatory marker such as TNF-α did not exhibit such changes.
Conclusion
Our study suggests: a) Chronic treatment of endothelial cells with IL-6 results in insulin resistance b) Neutrophil conditioned medium and IL-6 decreases methyl cytosine levels c) DNMT1 but not DNMT3a levels are reduced in cells treated with IL-6.
 Vural Özdemir, MD, Ph.D., DABCP
Vural Özdemir, MD, Ph.D., DABCP
Co-Founder, DELSA Global, Seattle, WA, USA
Crowd-Funded Micro-Grants to Link Biotechnology and “Big Data” R&D to Life Sciences Innovation in India
Vural Özdemir, MD, PhD, DABCP1,2*
- Data-Enabled Life Sciences Alliance International (DELSA Global), Seattle, WA 98101, USA;
- Faculty of Management and Medicine, McGill University, Canada;
ABSTRACT
Aims: This presentation proposes two innovative funding solutions for linking biotechnology and “Big Data” R&D in India with artisan small scale discovery science, and ultimately, with knowledge-based innovation:
- crowd-funded micro-grants, and
- citizen philanthropy
These two concepts are new, and inter-related, and can be game changing to achieve the vision of biotechnology innovation in India, and help bridge local innovation with global science.
Background and Context: Biomedical science in the 21(st) century is embedded in, and draws from, a digital commons and “Big Data” created by high-throughput Omics technologies such as genomics. Classic Edisonian metaphors of science and scientists (i.e., “the lone genius” or other narrow definitions of expertise) are ill equipped to harness the vast promises of the 21(st) century digital commons. Moreover, in medicine and life sciences, experts often under-appreciate the important contributions made by citizen scholars and lead users of innovations to design innovative products and co-create new knowledge. We believe there are a large number of users waiting to be mobilized so as to engage with Big Data as citizen scientists-only if some funding were available. Yet many of these scholars may not meet the meta-criteria used to judge expertise, such as a track record in obtaining large research grants or a traditional academic curriculum vitae. This presentation will describe a novel idea and action framework: micro-grants, each worth $1000, for genomics and Big Data. Though a relatively small amount at first glance, this far exceeds the annual income of the “bottom one billion” – the 1.4 billion people living below the extreme poverty level defined by the World Bank ($1.25/day).
We will present two types of micro-grants. Type 1 micro-grants can be awarded through established funding agencies and philanthropies that create micro-granting programs to fund a broad and highly diverse array of small artisan labs and citizen scholars to connect genomics and Big Data with new models of discovery such as open user innovation. Type 2 micro-grants can be funded by existing or new science observatories and citizen think tanks through crowd-funding mechanisms described herein. Type 2 micro-grants would also facilitate global health diplomacy by co-creating crowd-funded micro-granting programs across nation-states in regions facing political and financial instability, while sharing similar disease burdens, therapeutics, and diagnostic needs. We report the creation of ten Type 2 micro-grants for citizen science and artisan labs to be administered by the nonprofit Data-Enabled Life Sciences Alliance International (DELSA Global, Seattle: http://www.delsaglobal.org). Our hope is that these micro-grants will spur novel forms of disruptive innovation and life sciences translation by artisan scientists and citizen scholars alike.
Address Correspondence to:
Vural Özdemir, MD, PhD, DABCP
Senior Scholar and Associate Professor
Faculty of Management and Medicine, McGill University
1001 Sherbrooke Street West
Montreal, Canada H3A 1G5
Email: vural.ozdemir@alumni.utoronto.ca




Tejaswini Subbannayya, Nandini A. Sahasrabuddhe, Arivusudar Marimuthu, Santosh Renuse, Gajanan Sathe, Srinivas M. Srikanth, Mustafa A. Barbhuiya, Bipin Nair, Juan Carlos Roa, Rafael Guerrero-Preston, H. C. Harsha, David Sidransky, Akhilesh Pandey, T. S. Keshava Prasad and Aditi Chatterjee
Proteomic profiling of gallbladder cancer secretome – a source for circulatory biomarker discovery
Gallbladder cancer (GBC) is the fifth most common cancer of the gastrointestinal tract and one of the common malignancies that occur in the biliary tract (Misra et al. 2006; Lazcano-Ponce et al. 2001). It has a poor prognosis with survival of less than 5 years in 90% of the cases (Misra et al. 2003). The etiology is ill-defined. Several risk factors have been reported including cholelithiasis, obesity, female gender and exposure to carcinogens (Eslick 2010; Kumar et al. 2006). Poor prognosis in GBC is mainly due to late presentation of the disease and lack of reliable biomarkers for early diagnosis. This emphasizes the need to identify and characterize cancer biomarkers to aid in the diagnosis and prognosis of GBC. Secreted proteins are an important class of molecules which can be detected in body fluids and has been targeted for biomarker discovery. There are challenges faced in the proteomic interrogation of body fluids especially plasma such as low abundance of tumor secreted proteins, high complexity and high abundance of other proteins that are not released by the tumor cells (Tonack et al. 2009). Profiling of conditioned media from the cancer cell lines can be used as an alternate means to identify secreted proteins from tumor cells (Kashyap et al. 2010; Marimuthu et al. 2012). We analyzed the invasive property of 7 GBC cell lines (SNU-308, G-415, GB-d1, TGBC2TKB, TGBC24TKB, OCUG-1 and NOZ). Four cell lines were selected for analysis of the cancer secretome based on the invasive property of the cells. We employed isobaric tags for relative and absolute quantitation (iTRAQ) labeling technology coupled with high resolution mass spectrometry to identify and characterize secretome from the panel of 4GBC cancer cells mentioned above. In total, we have identified around 2,000 proteins of which 175 were secreted at differential abundance across all the four cell lines. This secretome analysis will act as a reservoir of candidate biomarkers. Currently, we are investigating and validating these candidate markers from GBC cell secretome. Through this study, we have shown mass spectrometry-based quantitative proteomic analysis as a robust approach to investigate secreted proteins in cancer cells.