 S. Ramaswamy, Ph.D.
S. Ramaswamy, Ph.D.
CEO of c-CAMP, Dean, inStem, NCBS, Bangalore, India
Discovery, engineering and applications of Blue Fish Protein with Red Fluorescence
Swagatha Ghosh, Chi-Li Yu, Daniel Ferraro, Sai Sudha, Wayne Schaefer, David T Gibson and S. Ramaswamy
Fluorescent proteins and their applications have revolutionized our understanding of biology significantly. In spite of several years since the discovery of the classic GFP, proteins of this class are used as the standard flag bearers. We have recently discovered a protein from the fish Sanders vitrius that shows interesting fluorescent properties – including a 280 nm stoke shift and infrared emission. The crystal structure of the wild type protein shows that it is a tetramer. We have engineered mutations to make a monomer with very similar fluorescent properties. We have used this protein for tissue imaging as well as for in cell-fluorescence successfully




 Ganesh Sambasivam, Ph.D.
Ganesh Sambasivam, Ph.D.
CSO & Co-Founder, Anthem Biosciences India
Preclinical Outsourcing to India
The outsourcing segment is witnessing rapid changes with respect to the nature of work outsourced and the location. Cost is the major driver but other considerations such as infrastructure and government policies can also be important drivers for decision making. The last couple of years have been a trying time for all CROs. The global economic meltdown has hit research budgets especially hard. The new challenges facing Contract Research Organizations call for a radically revised approach and a new model that would push the boundaries of this business further and would blur the line between client and vendor further. I believe the term Contract Research Organization (CRO), is a misnomer to begin with (often confused with Clinical Research Organization), has now morphed into a new type of company viz Contract Innovation Services (CIS). Clients are no longer just happy to outsource odds and ends of the development piece but are looking to their vendors for a massive amount of innovation input. This input is increasingly across both the chemistry and discovery domains. This new paradigm calls for CIS companies to develop new platforms, create intellectual propertythat is of service to clients andinnovate processes to meet new found customer expectations.
 Terry Hermiston, Ph.D.
Terry Hermiston, Ph.D.
Vice President, US Biologics Research Site Head, US Innovation Center Bayer Healthcare, USA
ColoAd1 – An oncolytic adenovirus derived by directed evolution
Attempts at developing oncolytic viruses have been primarily based on rational design. However, this approach has been met with limited success. An alternative approach employs directed evolution as a means of producing highly selective and potent anticancer viruses. In this method, viruses are grown under conditions that enrich and maximize viral diversity and then passaged under conditions meant to mimic those encountered in the human cancer microenvironment. Using the “Directed Evolution” methodology, we have generated ColoAd1, a novel chimeric oncolytic adenovirus. In vitro, this virus demonstrated a >2 log increase in both potency and selectivity when compared to ONYX-015 on colon cancer cells. These results were further supported by in vivo and ex vivo studies. Importantly, these results have validated this methodology as a new general approach for deriving clinically-relevant, highly potent anti-cancer virotherapies. This virus is currently in clinical trials as a novel treatment for cancer.


 Sanjeeva Srivastava, Ph.D.
Sanjeeva Srivastava, Ph.D.
Assistant Professor, Proteomics Lab, IIT-Bombay, India
Identification of Potential Early Diagnostic Biomarkers for Gliomas and Various Infectious Diseases using Proteomic Technologies
The spectacular advancements achieved in the field of proteomics research during the last decade have propelled the growth of proteomics for clinical research. Recently, comprehensive proteomic analyses of different biological samples such as serum or plasma, tissue, CSF, urine, saliva etc. have attracted considerable attention for the identification of protein biomarkers as early detection surrogates for diseases (Ray et al., 2011). Biomarkers are biomolecules that can be used for early disease detection, differentiation between closely related diseases with similar clinical manifestations as well as aid in scrutinizing disease progression. Our research group is performing in-depth analysis of alteration in human proteome in different types of brain tumors and various pathogenic infections to obtain mechanistic insight about the disease pathogenesis and host immune responses, and identification of surrogate protein markers for these fatal human diseases.
Applying 2D-DIGE in combination with MALDI-TOF/TOF MS we have analyzed the serum and tissue proteome profiles of glioblastoma multiforme; the most common and lethal adult malignant brain tumor (Gollapalli et al., 2012) (Figure 1). Results obtained were validated by employing different immunoassay-based approaches. In serum proteomic analysis we have identified some interesting proteins like haptoglobin, ceruloplasmin, vitamin-D binding protein etc. Moreover, proteomic analysis of different grades (grade-I to IV) of gliomas and normal brain tissue was performed and differential expressions of quite a few proteins such as SIRT2, GFAP, SOD, CDC42 have been identified, which have significant correlation with the tumor growth. While proteomic analysis of cerebrospinal fluid from low grade (grade I & II) vs. high grade (grade III & IV) gliomas revealed modulation of CSF levels of apolipoprotein E, dickkopf related protein 3, vitamin D binding protein and albumin in high grade gliomas. The prospective candidates identified in our studies provide a mechanistic insight of glioma pathogenesis and identification of potential biomarkers. We are also studying the role of JAK/STAT interactome and therapeutic potential of STAT3 inhibitors in gliomas using proteomics approach. Several candidates of the JAK/STAT interactome were identified with altered expression and a significant correlation was observed between STAT3 and PDK1 transcript expression level.
We have also investigated the changes in human serum proteome in different infectious diseases including falciparum and vivax malaria (Ray et al., 2012a; Ray et al., 2012b), dengue (Ray et al., 2012c) and leptospirosis (Srivastava et al., 2012). Although, quite a few serum proteins were found to be commonly altered in different infectious diseases and might be a consequence of inflammation mediated acute phase response signaling, uniquely modulated candidates were identified in each pathogenic infection indicating the some inimitable responses. Further, a panel of identified proteins consists of six candidates; serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I was used to build statistical sample class prediction models employing PLSDA and other classification methods to predict the clinical phenotypic classes and 91.37% overall prediction accuracy was achieved (Figure 2). ROC curve analysis was carried out to evaluate the individual performance of classifier proteins. The excellent discrimination among the different disease groups on the basis of differentially expressed proteins demonstrates the potential diagnostic implications of this analytical approach.
Keywords: Diagnostic biomarkers, Gliomas, Infectious Diseases, Proteomics, Serum proteome
Acknowledgments: This disease biomarker discovery research was supported by Department of Biotechnology, India grant (No. BT/PR14359/MED/30/916/2010), Board of Research in Nuclear Sciences (BRNS) DAE young scientist award (2009/20/37/4/BRNS) and a startup grant 09IRCC007 from the IIT Bombay. The active support from Advanced Center for Treatment Research and Education in Cancer (ACTREC), Tata Memorial Hospital (TMH), and Seth GS Medical College and KEM Hospital Mumbai, India in clinical sample collection process is gratefully acknowledged.
References :
- Ray S, Reddy PJ, Jain R, Gollapalli K. Moiyadi A, Srivastava S. Proteomic technologies for the identification of disease biomarkers in serum: advances and challenges ahead. Proteomics 11: 2139-61, 2011.
- Gollapalli K, Ray S, Srivastava R, Renu D, Singh P, Dhali S, Dikshit JB, Srikanth R, Moiyadi A, Srivastava S. Investigation of serum proteome alterations in human glioblastoma multiforme. Proteomics 12(14): 2378-90, 2012.
- Ray S, Renu D, Srivastava R, Gollapalli K, Taur S, Jhaveri T, Dhali S, Chennareddy S, Potla A, Dikshit JB, Srikanth R, Gogtay N, Thatte U, Patankar S, Srivastava S. Proteomic investigation of falciparum and vivax malaria for identification of surrogate protein markers. PLoS One 7(8): e41751, 2012a.
- Ray S, Kamath KS, Srivastava R, Raghu D, Gollapalli K, Jain R, Gupta SV, Ray S, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Patankar S, Srivastava S. Serum proteome analysis of vivax malaria: An insight into the disease pathogenesis and host immune response. J Proteomics 75(10): 3063-80, 2012b.
- Srivastava R, Ray S, Vaibhav V, Gollapalli K, Jhaveri T, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Srivastava S. Serum profiling of leptospirosis patients to investigate proteomic alterations. J Proteomics 76: 56-68, 2012.
- Ray S, Srivastava R, Tripathi K, Vaibhav V, Srivastava S. Serum proteome changes in dengue virus-infected patients from a dengue-endemic area of India: towards new molecular targets? OMICS 16(10): 527-36, 2012c.
* Correspondence: Dr. Sanjeeva Srivastava, Department of Biosciences and Bioengineering, IIT Bombay, Mumbai 400 076, India: E-mail: sanjeeva@iitb.ac.in; Phone: +91-22-2576-7779, Fax: +91-22-2572-3480
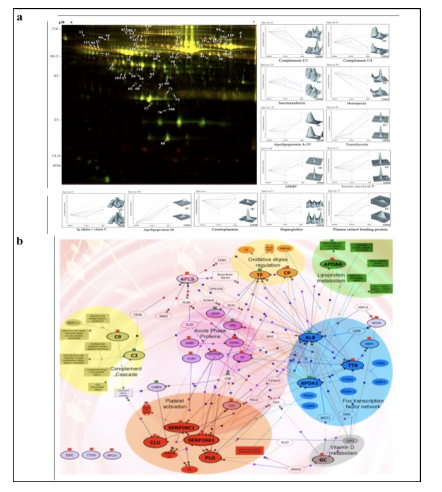
![Figure 2 (a) Western blot analysis of haptoglobin (HP), serum amyloid A (SAA), and clusterin (CLU) from serum samples of healthy control (HC) [n = 12], falciparum malaria (FM) [n = 12], vivax malaria (VM) [n = 12], Leptospirosis (Lep) [n = 6], dengue fever [DF] [n = 6] and non infectious disease control (NIDC:GBM) [n = 12]. Representative blots of the target proteins are depicted along with their respective relative abundance volumes (volume X 104). All the data are represented as mean ± SE. (b) Discrimination of malaria from dengue, leptospirosis and GBM using PLS-DA analysis. PLS-DA scores Plot for FM (blue spheres, n = 8), VM (green spheres, n = 8), DF (red spheres, n = 6), Lep (grey spheres, n = 6) and GBM (brown spheres, n = 8) samples based on 6 differentially expressed proteins (serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I) identified using DIGE. The axes of the plot indicate PLSDA latent variables t0-t2.](http://www.amritabioquest.org/conference/2013/wp-content/uploads/sites/2/2015/02/sanjeeva-2.jpg)


 Jaap Heringa, Ph.D.
Jaap Heringa, Ph.D.
Director & Professor of Bioinformatics, IBIVU VU University Amsterdam, The Netherlands
Modeling strategy based on Petri-nets
In my talk I will introduce a formal modeling strategy based on Petri-nets, which are a convenient means of modeling biological processes. I will illustrate the capabilities of Petri-nets as reasoning vehicles using two examples: Haematopoietic stem cell differentiation in mice, and vulval development in C. elegance. The first system was modeled using a Boolean implementation, and the second using a coarse-grained multi-cellular Petri-net model. Concepts such as the model state space, attractor states, and reasoning to adapt the model to the biological reality will be discussed.

 Nader Pourmand, Ph.D.
Nader Pourmand, Ph.D.
Director, UCSC Genome Technology Center,University of California, Santa Cruz
Biosensor and Single Cell Manipulation using Nanopipettes
Approaching sub-cellular biological problems from an engineering perspective begs for the incorporation of electronic readouts. With their high sensitivity and low invasiveness, nanotechnology-based tools hold great promise for biochemical sensing and single-cell manipulation. During my talk I will discuss the incorporation of electrical measurements into nanopipette technology and present results showing the rapid and reversible response of these subcellular sensors to different analytes such as antigens, ions and carbohydrates. In addition, I will present the development of a single-cell manipulation platform that uses a nanopipette in a scanning ion-conductive microscopy technique. We use this newly developed technology to position the nanopipette with nanoscale precision, and to inject and/or aspirate a minute amount of material to and from individual cells or organelle without comprising cell viability. Furthermore, if time permits, I will show our strategy for a new, single-cell DNA/ RNA sequencing technology that will potentially use nanopipette technology to analyze the minute amount of aspirated cellular material.
 Srisairam Achuthan, Ph.D.
Srisairam Achuthan, Ph.D.
Senior Scientific Programmer, Research Informatics Division, Department of Information Sciences, City of Hope, CA, USA
Applying Machine learning for Automated Identification of Patient Cohorts
Srisairam Achuthan, Mike Chang, Ajay Shah, Joyce Niland
Patient cohorts for a clinical study are typically identified based on specific selection criteria. In most cases considerable time and effort are spent in finding the most relevant criteria that could potentially lead to a successful study. For complex diseases, this process can be more difficult and error prone since relevant features may not be easily identifiable. Additionally, the information captured in clinical notes is in non-coded text format. Our goal is to discover patterns within the coded and non-coded fields and thereby reveal complex relationships between clinical characteristics across different patients that would be difficult to accomplish manually. Towards this, we have applied machine learning techniques such as artificial neural networks and decision trees to determine patients sharing similar characteristics from available medical records. For this proof of concept study, we used coded and non-coded (i.e., clinical notes) patient data from a clinical database. Coded clinical information such as diagnoses, labs, medications and demographics recorded within the database were pooled together with non-coded information from clinical notes including, smoking status, life style (active / inactive) status derived from clinical notes. The non-coded textual information was identified and interpreted using a Natural Language Processing (NLP) tool I2E from Linguamatics.