


 Sanjeeva Srivastava, Ph.D.
Sanjeeva Srivastava, Ph.D.
Assistant Professor, Proteomics Lab, IIT-Bombay, India
Identification of Potential Early Diagnostic Biomarkers for Gliomas and Various Infectious Diseases using Proteomic Technologies
The spectacular advancements achieved in the field of proteomics research during the last decade have propelled the growth of proteomics for clinical research. Recently, comprehensive proteomic analyses of different biological samples such as serum or plasma, tissue, CSF, urine, saliva etc. have attracted considerable attention for the identification of protein biomarkers as early detection surrogates for diseases (Ray et al., 2011). Biomarkers are biomolecules that can be used for early disease detection, differentiation between closely related diseases with similar clinical manifestations as well as aid in scrutinizing disease progression. Our research group is performing in-depth analysis of alteration in human proteome in different types of brain tumors and various pathogenic infections to obtain mechanistic insight about the disease pathogenesis and host immune responses, and identification of surrogate protein markers for these fatal human diseases.
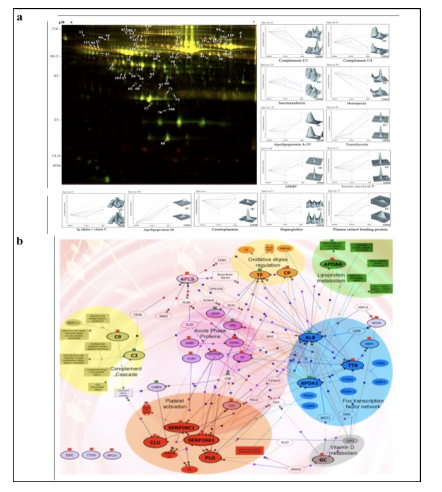
Applying 2D-DIGE in combination with MALDI-TOF/TOF MS we have analyzed the serum and tissue proteome profiles of glioblastoma multiforme; the most common and lethal adult malignant brain tumor (Gollapalli et al., 2012) (Figure 1). Results obtained were validated by employing different immunoassay-based approaches. In serum proteomic analysis we have identified some interesting proteins like haptoglobin, ceruloplasmin, vitamin-D binding protein etc. Moreover, proteomic analysis of different grades (grade-I to IV) of gliomas and normal brain tissue was performed and differential expressions of quite a few proteins such as SIRT2, GFAP, SOD, CDC42 have been identified, which have significant correlation with the tumor growth. While proteomic analysis of cerebrospinal fluid from low grade (grade I & II) vs. high grade (grade III & IV) gliomas revealed modulation of CSF levels of apolipoprotein E, dickkopf related protein 3, vitamin D binding protein and albumin in high grade gliomas. The prospective candidates identified in our studies provide a mechanistic insight of glioma pathogenesis and identification of potential biomarkers. We are also studying the role of JAK/STAT interactome and therapeutic potential of STAT3 inhibitors in gliomas using proteomics approach. Several candidates of the JAK/STAT interactome were identified with altered expression and a significant correlation was observed between STAT3 and PDK1 transcript expression level.
We have also investigated the changes in human serum proteome in different infectious diseases including falciparum and vivax malaria (Ray et al., 2012a; Ray et al., 2012b), dengue (Ray et al., 2012c) and leptospirosis (Srivastava et al., 2012). Although, quite a few serum proteins were found to be commonly altered in different infectious diseases and might be a consequence of inflammation mediated acute phase response signaling, uniquely modulated candidates were identified in each pathogenic infection indicating the some inimitable responses. Further, a panel of identified proteins consists of six candidates; serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I was used to build statistical sample class prediction models employing PLSDA and other classification methods to predict the clinical phenotypic classes and 91.37% overall prediction accuracy was achieved (Figure 2). ROC curve analysis was carried out to evaluate the individual performance of classifier proteins. The excellent discrimination among the different disease groups on the basis of differentially expressed proteins demonstrates the potential diagnostic implications of this analytical approach.
Keywords: Diagnostic biomarkers, Gliomas, Infectious Diseases, Proteomics, Serum proteome
Acknowledgments: This disease biomarker discovery research was supported by Department of Biotechnology, India grant (No. BT/PR14359/MED/30/916/2010), Board of Research in Nuclear Sciences (BRNS) DAE young scientist award (2009/20/37/4/BRNS) and a startup grant 09IRCC007 from the IIT Bombay. The active support from Advanced Center for Treatment Research and Education in Cancer (ACTREC), Tata Memorial Hospital (TMH), and Seth GS Medical College and KEM Hospital Mumbai, India in clinical sample collection process is gratefully acknowledged.
References :
- Ray S, Reddy PJ, Jain R, Gollapalli K. Moiyadi A, Srivastava S. Proteomic technologies for the identification of disease biomarkers in serum: advances and challenges ahead. Proteomics 11: 2139-61, 2011.
- Gollapalli K, Ray S, Srivastava R, Renu D, Singh P, Dhali S, Dikshit JB, Srikanth R, Moiyadi A, Srivastava S. Investigation of serum proteome alterations in human glioblastoma multiforme. Proteomics 12(14): 2378-90, 2012.
- Ray S, Renu D, Srivastava R, Gollapalli K, Taur S, Jhaveri T, Dhali S, Chennareddy S, Potla A, Dikshit JB, Srikanth R, Gogtay N, Thatte U, Patankar S, Srivastava S. Proteomic investigation of falciparum and vivax malaria for identification of surrogate protein markers. PLoS One 7(8): e41751, 2012a.
- Ray S, Kamath KS, Srivastava R, Raghu D, Gollapalli K, Jain R, Gupta SV, Ray S, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Patankar S, Srivastava S. Serum proteome analysis of vivax malaria: An insight into the disease pathogenesis and host immune response. J Proteomics 75(10): 3063-80, 2012b.
- Srivastava R, Ray S, Vaibhav V, Gollapalli K, Jhaveri T, Taur S, Dhali S, Gogtay N, Thatte U, Srikanth R, Srivastava S. Serum profiling of leptospirosis patients to investigate proteomic alterations. J Proteomics 76: 56-68, 2012.
- Ray S, Srivastava R, Tripathi K, Vaibhav V, Srivastava S. Serum proteome changes in dengue virus-infected patients from a dengue-endemic area of India: towards new molecular targets? OMICS 16(10): 527-36, 2012c.
* Correspondence: Dr. Sanjeeva Srivastava, Department of Biosciences and Bioengineering, IIT Bombay, Mumbai 400 076, India: E-mail: sanjeeva@iitb.ac.in; Phone: +91-22-2576-7779, Fax: +91-22-2572-3480
![Figure 2 (a) Western blot analysis of haptoglobin (HP), serum amyloid A (SAA), and clusterin (CLU) from serum samples of healthy control (HC) [n = 12], falciparum malaria (FM) [n = 12], vivax malaria (VM) [n = 12], Leptospirosis (Lep) [n = 6], dengue fever [DF] [n = 6] and non infectious disease control (NIDC:GBM) [n = 12]. Representative blots of the target proteins are depicted along with their respective relative abundance volumes (volume X 104). All the data are represented as mean ± SE. (b) Discrimination of malaria from dengue, leptospirosis and GBM using PLS-DA analysis. PLS-DA scores Plot for FM (blue spheres, n = 8), VM (green spheres, n = 8), DF (red spheres, n = 6), Lep (grey spheres, n = 6) and GBM (brown spheres, n = 8) samples based on 6 differentially expressed proteins (serum amyloid A, hemopexin, apolipoprotein E, haptoglobin, retinol-binding protein and apolipoprotein A-I) identified using DIGE. The axes of the plot indicate PLSDA latent variables t0-t2.](http://www.amritabioquest.org/conference/2013/wp-content/uploads/sites/2/2015/02/sanjeeva-2.jpg)


 Nader Pourmand, Ph.D.
Nader Pourmand, Ph.D.
Director, UCSC Genome Technology Center,University of California, Santa Cruz
Biosensor and Single Cell Manipulation using Nanopipettes
Approaching sub-cellular biological problems from an engineering perspective begs for the incorporation of electronic readouts. With their high sensitivity and low invasiveness, nanotechnology-based tools hold great promise for biochemical sensing and single-cell manipulation. During my talk I will discuss the incorporation of electrical measurements into nanopipette technology and present results showing the rapid and reversible response of these subcellular sensors to different analytes such as antigens, ions and carbohydrates. In addition, I will present the development of a single-cell manipulation platform that uses a nanopipette in a scanning ion-conductive microscopy technique. We use this newly developed technology to position the nanopipette with nanoscale precision, and to inject and/or aspirate a minute amount of material to and from individual cells or organelle without comprising cell viability. Furthermore, if time permits, I will show our strategy for a new, single-cell DNA/ RNA sequencing technology that will potentially use nanopipette technology to analyze the minute amount of aspirated cellular material.
 Kal Ramnarayan, Ph.D.
Kal Ramnarayan, Ph.D.
Co-founder President & Chief Scientific Officer, Sapient Discovery, San Diego, CA, USA
A cost-effective approach to Protein Structure-guided Drug Discovery: Aided by Bioinformatics, Chemoinformatics and computational chemistry
With the mapping of the human genome completed almost a decade ago, efforts are still underway to understand the gene products (i.e., proteins) in the human biological and disease pathways. Deciphering such information is very important for the discovery and development of small molecule drugs as well as protein therapeutics for various human diseases for which no cure exists. As an example, with more than 500 members, the kinase family of protein targets continues to be an important and attractive class for drug discovery. While how many of the members in this family are actually druggable is still to be established, there are several ongoing efforts on this class of proteins across a broad spectrum of disease categories. Even though in general the protein structural topology might looks similar, there are issues with respect selectivity of identified small molecule inhibitors when, the lead molecule discovery is carried out at the ATP binding site. As an added complexity, allosteric modulators are needed for some of the members, but the actual site for such modulation on the protein target can not resolved with uncertainty. In this presentation we will describe a bioinformatics and computational based platform for small molecule discovery for protein targets that are involved in protein-protein interactions as well as targets like kinases and phosphatases. We will describe a computational approach in which we have used an informatics based platform with several hundred kinases to sort through in silico and identify inhibitors that are likely to be highly selective in the lead generation phase. We will discuss the implication of this approach on the drug discovery of the kinase and phosphatase classes in general and independent of the disease category.

Sunilkumar Sukumaran, Ayyappan Nair, Madhuri Subbiah, Gunja Gupta, Lakshmi Rajakrishna, Pradeep Savanoor Raghavendra, Subbulakshmi Karthikeyan, Salini Krishnan Unni and Ganesh Sambasivam
Genotoxicity is defined as DNA damage that leads to gene mutations which can become tumorigenic. Genotoxicity testing is important to ensure drug safety and is mandatory prior to Phase I/II clinical trials of new drugs. The results from genetic toxicology studies help to identify hazardous drugs and environmental genotoxins. Currently, among others there are four tests recommended by regulatory authorities (Ames test-bacterial, chromosome aberrations; in vitro gene mutation-eukaryotic cells and in vivo test). These assays are laborious, time consuming, require large quantities of test compounds and limited by throughput challenges. The site and mechanism of genotoxicity are not revealed by these assays and data obtained from bacterial tests might not translate the same in mammals. To address these we have developed a novel, versatile, human cell based, high throughput, reporter based genotoxicity screen (Anthem’s Genotox screen). This screen is performed on genetically engineered human cell lines that express 3 reporter genes under transcriptional control of ‘early DNA damage sensors’ (p53, p21 and GADD153). These genes are involved in DNA repair, cell cycle arrest and/or apoptosis. p21 and GADD are also known to be induced in a p53 independent manner. p53 blocks G1/S transition of cell cycle while the p53 independent DNA damage block G2/M transition. Identification of the mechanism of genotoxicity helps in rational drug designing. Additionally, the platform can be used to screen other potential genotoxins from cosmetics, food and environment. Initial validation studies of the Genotox screen was performed with over 60 compounds chosen from a variety of chemical classes. The genotoxic potential of metabolites was tested using rat liver S9 fractions. The results demonstrated a sensitivity of 86.7–92.3% and a specificity of 70–78.6% when compared with currently available in vitro genotoxicity assays. This Genotox screen would prove to be an invaluable human cell based tool to weed out potential genotoxins in various industries.
 Akhilesh Pandey, Ph.D.
Akhilesh Pandey, Ph.D.
Professor, Johns Hopkins University School of Medicine, Baltimore, USA
A draft map of the human proteome
We have generated a draft map of the human proteome through a systematic and comprehensive analysis of normal human adult tissues, fetal tissues and hematopoietic cells as an India-US initiative. This unique dataset was generated from 30 histologically normal adult tissues, fetal tissues and purified primary hematopoietic cells that were analyzed at high resolution in the MS mode and by HCD fragmentation in the MS/MS mode on LTQ-Orbitrap Velos/Elite mass spectrometers. This dataset was searched against a 6-frame translation of the human genome and RNA-Seq transcripts in addition to standard protein databases. In addition to confirming a large majority (>16,000) of the annotated protein-coding genes in humans, we obtained novel information at multiple levels: novel protein-coding genes, unannotated exons, novel splice sites, proof of translation of pseudogenes (i.e. genes incorrectly annotated as pseudogenes), fused genes, SNPs encoded in proteins and novel N-termini to name a few. Many proteins identified in this study were identified by proteomic methods for the first time (e.g. hypothetical proteins or proteins annotated based solely on their chromosomal location). We have generated a catalog of proteins that show a more tissue-restricted pattern of expression, which should serve as the basis for pursuing biomarkers for diseases pertaining to specific organs. This study also provides one of the largest sets of proteotypic peptides for use in developing MRM assays for human proteins. Identification of several novel protein-coding regions in the human genome underscores the importance of systematic characterization of the human proteome and accurate annotation of protein-coding genes. This comprehensive dataset will complement other global HUPO initiatives using antibody-based as well as MRM mass spectrometry-based strategies. Finally, we believe that this dataset will become a reference set for use as a spectral library as well as for interesting interrogations pertaining to biomedical as well as bioinformatics questions.
